



VLLM Gemma 2b Batch Performance on Tesla T4
Model: google/gemma-2b-it Accelerator: NVIDIA Tesla T4 GPU Host: 3 × n1-standard-8 (8 vCPUs, 30 GB RAM)
The following graphs show various metrics when running VLLM Gemma 2b Batch Performance on Tesla T4 pipeline. See the glossary for definitions.
Full pipeline implementation is available here.
What is the estimated cost to run the pipeline?
RunTime and EstimatedCost
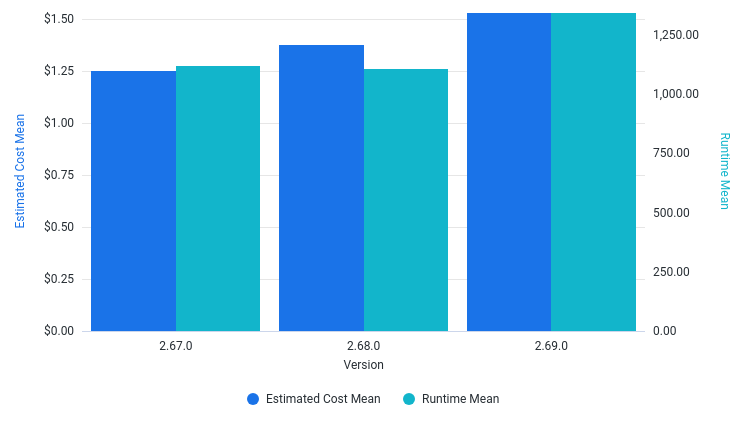
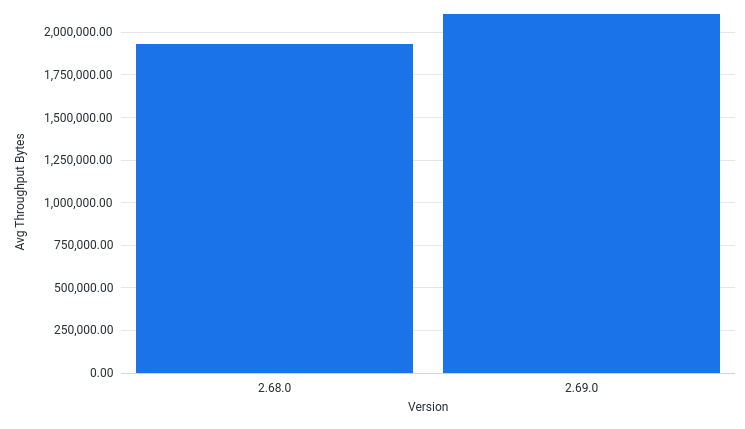
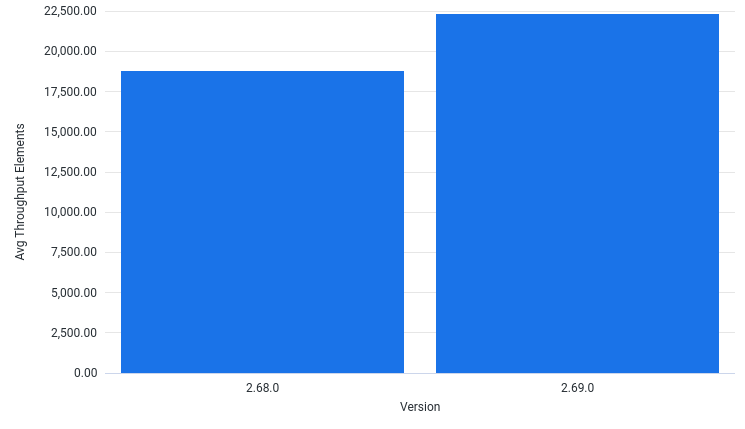
How has various metrics changed when running the pipeline for different Beam SDK versions?
AvgThroughputBytesPerSec by Version
AvgThroughputElementsPerSec by Version
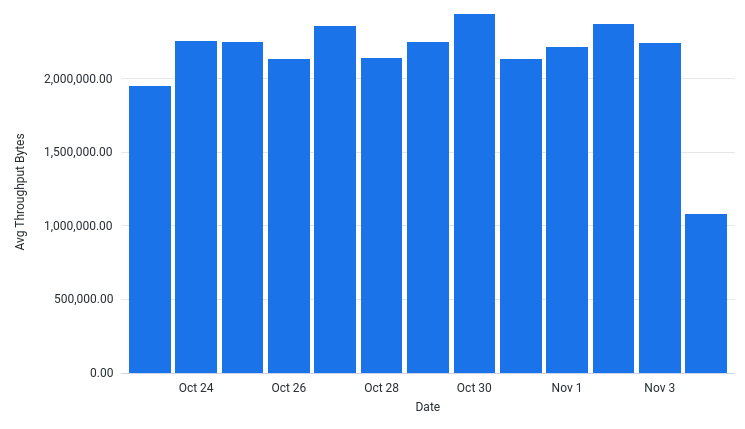
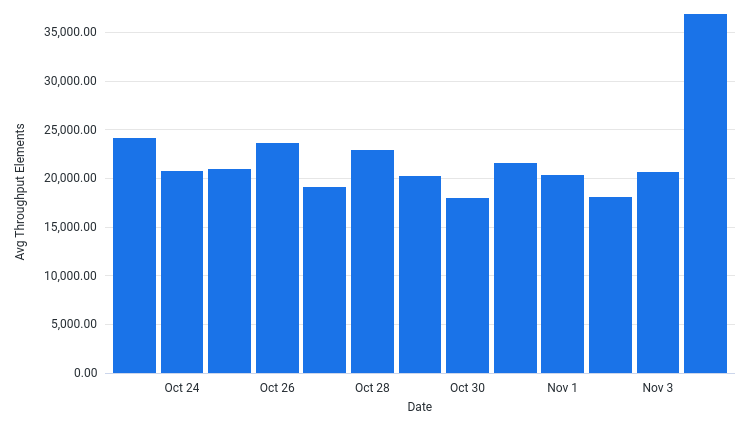
How has various metrics changed over time when running the pipeline?
AvgThroughputBytesPerSec by Date
AvgThroughputElementsPerSec by Date
Last updated on 2026/02/13
Have you found everything you were looking for?
Was it all useful and clear? Is there anything that you would like to change? Let us know!