




“At Yelp, Apache Beam provides an option for different teams to create custom streaming pipelines using Python, eliminating the need to switch to Scala or Java. This reduces the learning curve for Python developers and minimizes friction, while providing the flexibility to utilize existing Python libraries.”

Building data abstractions with streaming at Yelp
Background
Yelp relies heavily on streaming to synchronize enormous volumes of data in real time. This is facilitated by Yelp’s underlying data pipeline infrastructure, which manages the real-time flow of millions of messages originating from a plethora of services. This blog post covers how we leverage Yelp’s extensive streaming infrastructure to build robust data abstractions for our offline and streaming data consumers. We will use Yelp’s Business Properties ecosystem (explained in the upcoming sections) as an example.
Key terminology
Let’s start by covering certain key terms used throughout the post:
Offline systems - data warehousing platforms such as AWS Redshift or Yelp’s Data Lake, which are intended for large-scale data analysis
Online systems - systems designed around high-performance SQL and NoSQL database solutions like MySQL or Cassandra DB, specifically built to handle and serve live traffic in real time, typically via REST APIs over HTTP. These databases are optimized for swiftly processing and delivering data as it’s generated or requested, making them crucial for applications and services that require immediate access to up-to-date information
Status Quo
Introduction to business properties ecosystem
Generally speaking, ‘Business Property’ can be any piece of data that is associated with a Yelp business. For example, if we’re talking about a restaurant, its business properties could include things like what payment methods it accepts, what amenities it provides, and when it is open for business.
There are two types of business properties: Business Attributes and Business Features. You may notice that the terms, attributes and features, are synonymous to each other, and that’s by no accident. The primary distinction is that Business Attributes belong to the legacy system, yelp-main, while Business Features are in a dedicated microservice, aligning with Yelp’s transition to Service Oriented Architecture.
We also gather additional metadata about business properties themselves, such as when they were last modified, how confident we are in their accuracy, and where they originated from. This additional information is referred to as “properties metadata.” We store this metadata in a separate table, which contains data about both Business Features and Business Attributes.
Business properties data is accessed via two primary methods: HTTP APIs for real-time online applications and streaming for offline data synchronization. This post mainly focuses on the streaming aspect.
Existing Business Properties’ streaming architecture

In yelp-main’s MySQL database, data for Business Attributes is scattered across more than a dozen tables. To share this data efficiently, we employ the MySQL Replication Handler to push it to Kafka
Business Features and metadata for business properties are stored in their respective tables in Cassandra db and we use Cassandra Source Connector to publish their data into Kafka
Ultimately, we use Redshift Connector to synchronize data from all these tables with their corresponding tables in Redshift. This process allows us to maintain an up-to-date dataset in Redshift for analysis and reporting
Challenges with the existing workflow
Weak Encapsulation: Storing data in offline systems exactly as it is stored in source databases forces our clients to understand the inner workings of the source data, which weakens data encapsulation. Ideally, we wanted to abstract away distinctions like ‘Business Features’ and ‘Business Attributes’ and hide implementation details from clients to simplify their interactions. Furthermore, exposing raw data to offline consumers can lead to the disclosure of outdated or incorrect information. Transformation layers via REST APIs prevented online users from facing data discrepancies. However, offline users analyzing raw data still had to grapple with data accuracy issues, such as managing soft-deleted entries.
Discovery and consumption: The lack of proper abstractions also made data analysis and consumption challenging as it meant that consumers, whether they are Product Managers, Data Analysts, or batch processing systems, must create multiple workflows to collect data from various sources. Not to mention, dealing with edge cases and transforming data into a consistent schema added significant effort and cost, leading to an increase in the friction for consumption and a reduction in the general utility of the data.
Maintenance challenges: It also posed certain maintenance challenges as any alteration in the source schema necessitated corresponding changes in the destination store. Ideally, we would prefer the destination store’s schema to be more flexible, dynamic, and less susceptible to changes. This minimizes disruptions for users and mitigates the risk of infrastructure problems due to frequent schema upgrades. It also underscores the fact that a storage schema suitable for one database system might not be ideal for another.
Improved Implementation:
We did explore various alternatives, including a non-streaming solution that involved using Apache Spark for routine batch executions to generate data dumps in diverse formats. However, as some of the data consumer use cases required relatively real-time updates, we had to lean towards a streaming approach.
Building robust data abstractions for both offline and streaming data consumers
We tackled the aforementioned challenges by treating both streaming and offline data consumption as just additional channels for accessing and utilizing data, much like online HTTP clients. Similar to how we simplify complexities for online data consumers through REST APIs, we aimed to provide a consistent experience for streamed data by abstracting away internal implementation details. This means that if a client service transitions from consuming data directly through REST APIs to an asynchronous streaming approach, it will encounter similar data abstractions. For example, just as online consumers won’t see stale or invalid data, the same principle applies to streamed data consumers.
In order to achieve the same, we implemented a unified stream that delivers all relevant business property data in a consistent and user-friendly format. This approach ensures that Business Property consumers are spared from navigating the nuances between Business Attributes and Features or understanding the intricacies of data storage in their respective online source databases.
New consolidated business properties streaming architecture
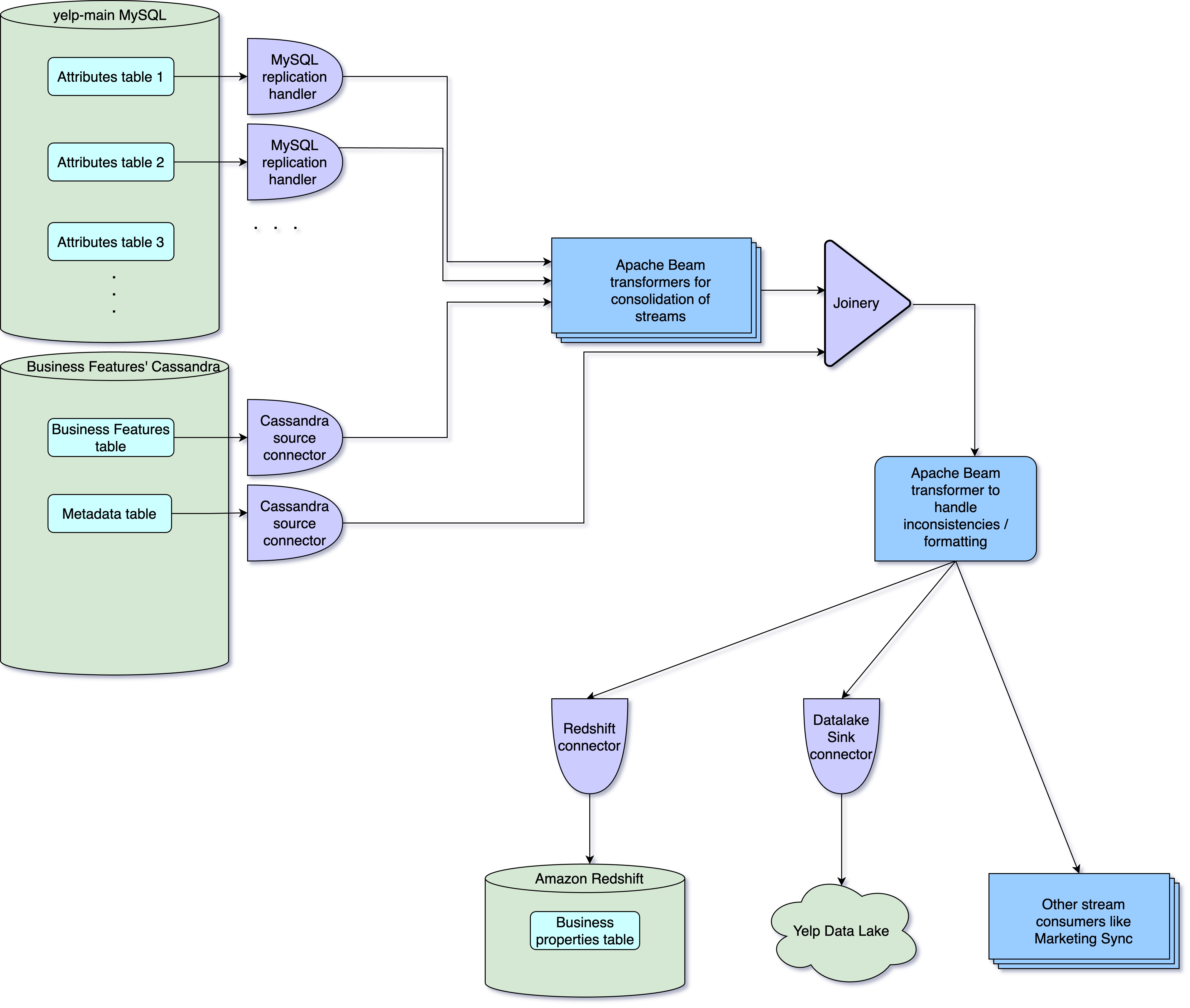
Business Attributes data collection and transformation: we utilize Apache Beam with Apache Flink as the distributed processing backend for data transformation and formatting Business attribute data. Apache Beam transformation jobs process data originating from various input streams generated by the MySQL replication handler. These streams contain replicated data from their corresponding MySQL tables. The transformation jobs are responsible for standardizing the incoming streaming data, transforming it into a consistent format across all business properties. The transformed data is then published into a single unified stream.
Streaming Business Features: in a similar fashion, the output stream for Business Features, sourced from Cassandra using a source connector, also has its dedicated Apache Beam transformer job. This job formats the data to match the unified format used for Business Attributes, and the resulting data is published into the same unified output stream
Enrich data with properties metadata: we employed a Joinery Flink job - a homegrown solution at Yelp commonly used for joining data across multiple Kafka topics - to amalgamate the business data for both Business Attributes and Features with the corresponding metadata. As a result, the data stream not only contains the business properties data but also the relevant metadata linked to each property.
Final data formatting: transformation job to address issues related to data inconsistencies, remove invalid data entries, and add any necessary supplementary fields, before the final business properties with metadata consolidated stream is exposed for consumption
Offline data storage: the processed business properties data, complete with metadata, is made available for offline consumption and ends up in Redshift, through Redshift Connector. Additionally, it is ingested into Yelp’s Data Lake using a Data Lake connector, making it available for a broader range of analytics and data processing tasks
Real-time consumption and Integration: the same consolidated data stream can cater to real-time consumption by other services within the organization. We use the same stream to sync business property data with Marketing systems, as they require timely syncs for their campaigns
To summarize, with the architecture described above, we have created a unified business properties stream addressing the challenges with the existing workflow mentioned above. This stream is utilized to sync business properties data into offline systems, enabling users to access all business properties through a singular schema, thereby facilitating data discovery, consumption, and overall ease of use.
Additionally, this approach allowed us to enrich business property data with associated metadata and resolve data inconsistencies, such as removing duplicate business properties etc. We used the entity–attribute–value (EAV) model, which accommodates the frequent introduction of new business properties without requiring modifications to the destination store schemas, hence reducing some of the maintenance overhead.
Final words
This post shows how Yelp’s robust data pipeline infrastructure can be leveraged to create sophisticated data pipelines that provide data in formats which are more suited and beneficial for both offline and streaming users. While this doesn’t imply that streaming and exposing raw data is never appropriate, however in such situations, it may be more effective to offer multiple streams: one with the raw data and others with processed data that is more befitting for data analysis and consumption
This blog post was originally published in March 2024 on Yelp’s Engineering Blog: Building Data Abstractions with Streaming at Yelp.
Was this information useful?