




“Without Beam, without all this data and real time information, we could not deliver the services we are providing and handle the volumes of data we are processing.”

Apache Beam Amplified Ricardo’s Real-time and ML Data Processing for eCommerce Platform.
Background
Ricardo is a leading second hand marketplace in Switzerland. The site supports over 4 million registered buyers and sellers, processing more than 6.5 million article transactions via the platform annually. Ricardo needs to process high volumes of streaming events and manage over 5 TB of articles, assets, and analytical data.
With the scale that came from 20 years in the market, Ricardo made the decision to migrate from their on-premises data center to cloud to easily grow and evolve further and reduce operational costs through managed cloud services. Data intelligence and engineering teams took the lead on this transformation and development of new AI/ML-enabled customer experiences. Apache Beam has been a technology amplifier that expedited Ricardo’s transformation.
Challenge
Migrating from an on-premises data center to the cloud presented Ricardo with an opportunity to modernize their marketplace from heavy legacy reliance on transactional SQL, switch to BigQuery for analytics, and take advantage of the event-based streaming architecture.
Ricardo’s data intelligence team identified two key success factors: a carefully designed data model and a framework that provides unified stream and batch data pipelines execution, both on-premises and in the cloud.
Ricardo needed a data processing framework that can scale easily, enrich event streams with historic data from multiple sources, provide granular control on data freshness, and provide an abstract pipeline operational infrastructure, thus helping their team focus on creating new value for customers and business
Journey to Beam
Ricardo’s data intelligence team began modernizing their stack in 2018. They selected frameworks that provide reliable and scalable data processing both on-premises and in the cloud. Apache Beam enables users to create pipelines in their favorite programming language offering SDKs in Java, Python, Go, SQL, Scala (SCIO). A Beam Runner runs a Beam pipeline on a specific (often distributed) data processing system. Ricardo selected the Apache Beam Flink runner for executing pipelines on-premises and the Dataflow runner as a managed cloud service for the same pipelines developed using Apache Beam Java SDK. Apache Flink is well known for its reliability and cost-efficiency and an on-premises cluster was spun up at Ricardo’s datacenter as the initial environment.
We wanted to implement a solution that would multiply our possibilities, and that’s exactly where Beam comes in. One of the major drivers in this decision was the ability to evolve without adding too much operational load.
Beam pipelines for core business workloads to ingest events data from Apache Kafka into BigQuery were running stable in just one month. As Ricardo’s cloud migration progressed, the data intelligence team migrated Flink cluster from Kubernetes in their on-premises datacenter to GKE.
I knew Beam, I knew it works. When you need to move from Kafka to BigQuery and you know that Beam is exactly the right tool, you just need to choose the right executor for it.
The flexibility to refresh data every hour, minute, or stream data real-time, depending on the specific use case and need, helped the team improve data freshness which was a significant advancement for Ricardo’s eCommerce platform analytics and reporting.
Ricardo’s team found benefits in Apache Beam Flink runner on self-managed Flink cluster in GKE for streaming pipelines. Full control over Flink provisioning enabled to set up required connectivity from Flink cluster to an external peered Kafka managed service. The data intelligence team optimized operating costs through cluster resource utilization significantly. For batch pipelines, the team chose Dataflow managed service for its on-demand autoscaling and cost reduction features like FlexRS, especially efficient for training ML models over TBs of historic data. This hybrid approach has been serving Ricardo’s needs well and proved to be a reliable production solution.
Evolution of Use Cases
Thinking of a stream as data in motion, and a table as data at rest provided a fortuitous chance to take a look at some data model decisions that were made as far back as 20 years before. Articles that are on the marketplace have assets that describe them, and for performance and cost optimizations purposes, data entities that belong together were split into separate database instances. Apache Beam enabled Ricardo’s data intelligence team to join assets and articles streams and optimize BigQuery scans to reduce costs. When designing the pipeline, the team created streams for assets and articles. Since the assets stream is the primary one, they shifted the stream 5 minutes back and created a lookup schema with it in BigTable. This elegant solution ensures that the assets stream is always processed first while BigTable allows for matching the latest asset to an article and Apache Beam joins them both together.
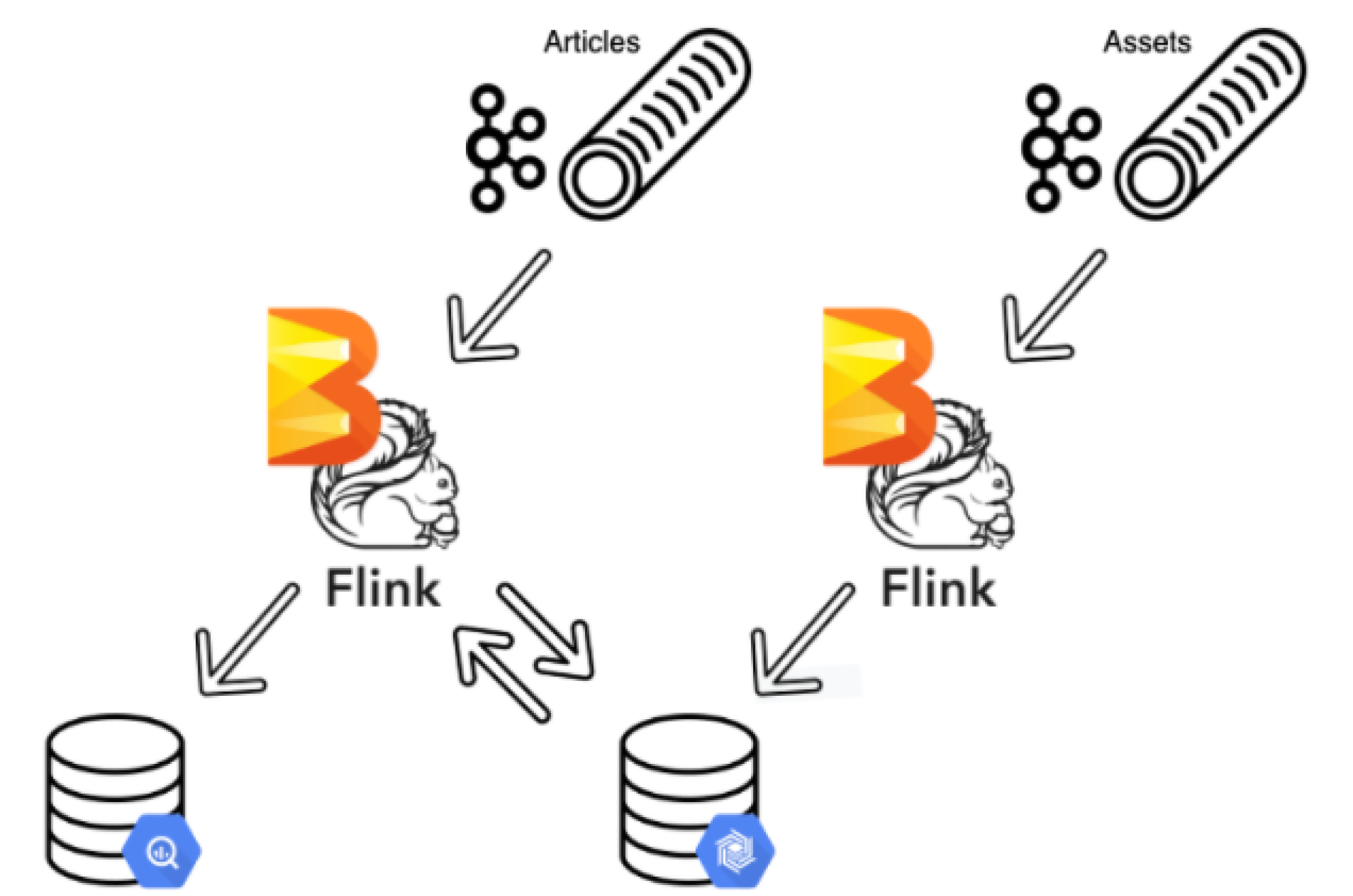
The successful case of joining different data streams facilitated further Apache Beam adoption by Ricardo in areas like data science and ML.
Once you start laying out the simple use cases, you will always figure out the edge case scenarios. This pipeline has been running for a year now, and Beam handles it all, from super simple use cases to something crazy.
As an eCommerce retailer, Ricardo faces the increasing scale and sophistication of fraud transactions and takes a strategic approach by employing Beam pipelines for fraud detection and prevention. Beam pipelines act on an external intelligent API to identify the signs of fraudulent behaviour, like device characteristics or user activity. Apache Beam stateful processing feature enables Ricardo to apply an associating operation to the streams of data (trigger banishing a user for example). Thus, Apache Beam saves Ricardo’s customer care team’s time and effort on investigating duplicate cases. It also runs batch pipelines to find linked accounts, associate products to categories by encapsulating a ML model, or calculates the likelihood something is going to sell, at a scale or precision that was previously not possible.
Originally implemented by Ricardo’s data intelligence team, Apache Beam has proven to be a powerful framework that supports advanced scenarios and acts as a glue between Kafka, BigQuery, and platform and external APIs, which encouraged other teams at Ricardo to adopt it.
[Apache Beam] is a framework that is so good that other teams are picking up the idea and starting to work with it after we tested it.
Results
Apache Beam has provided Ricardo with a scalable and reliable data processing framework that supported Ricardo’s fundamental business scenarios and enabled new use cases to respond to events in real-time.
Throughout Ricardo’s transformation, Apache Beam has been a unified framework that can run batch and stream pipelines, offers on-premises and cloud managed services execution, and programming language options like Java and Python, empowered data science and research teams to advance customer experience with new real-time scenarios fast-tracking time to value.
After this first pipeline, we are working on other use cases and planning to move them to Beam. I was always trying to spread the idea that this a framework that is reliable, it actually helps you to get the stuff done in a consistent way.
Apache Beam has been a technology that multiplied possibilities, allowing Ricardo to maximize technology benefits at all stages of their modernization and cloud journey.
Learn More
Was this information useful?