




“Apache Beam supports our mission to make the web a safer and better place by providing near-real-time visibility into traffic data for our customers, providing ongoing analysis and adjustments to our defenses, and neutralizing the impact of traffic spikes during DDoS attacks on the performance and efficiency of our platform.”

Efficient Streaming Analytics: Making the Web a Safer Place with Project Shield
Background
Project Shield, offered by Google Cloud and Jigsaw (a subsidiary of Google), is a service that counters distributed-denial-of-service (DDoS) attacks. Project Shield is available free of charge to eligible websites that have media, elections, and human rights related content. Founded in 2013, Project Shield’s mission is to protect freedom of speech and to make sure that, when people have access to democracy-related information, the information isn’t compromised, censored, or silenced in a politically-motivated way.
In the first half of 2022, Project Shield defended websites of vulnerable users - such as human rights, news, and civil society organizations or governments under exigent circumstances - against more than 25,000 attacks. Notably, Project Shield helped ensure unhindered access to election-related information during the U.S. 2022 midterm election season. It also enables Ukrainian critical infrastructure and media websites to defend against non-stop attacks and to continue providing crucial services and information during the invasion of Ukraine.
Marc Howard and Chad Hansen, the co-founding engineers, explain how Project Shield uses Apache Beam to deliver some of their core value. The streaming Apache Beam pipelines process about 3 TB of log data daily at significantly over 10,000 queries per second. These pipelines enable multiple product needs. For example, Apache Beam produces real-time analytics and critical metrics for over 3000 customer websites in 150 countries. These metrics power long-term attack analytics at scale, fine-tuning Project Shield’s defenses and supporting them in the effort of making the web a safe and free space.
Journey To Beam
The Project Shield platform is built using Google Cloud technologies and provides multi-layered defenses. To absorb part of the traffic and keep websites online even if their servers are down, it uses Cloud CDN for caching. To protect websites from DDoS and other malicious attacks, it leverages Cloud Armor features, such as adaptive protection, rate limiting, and bot management.
Project Shield acts as a reverse proxy: it receives traffic requests on a website’s behalf, absorbs traffic through caching, filters harmful traffic, bans attackers, and then sends safe traffic to a website’s origin server. This configuration allows websites to stay up and running when someone tries to take them down with a DDoS attack. The challenge is that, with a large portion of traffic blocked, the logs on customers’ origin servers no longer have accurate analytics about website traffic. Instead, customers rely on Project Shield to provide all of the traffic analytics.
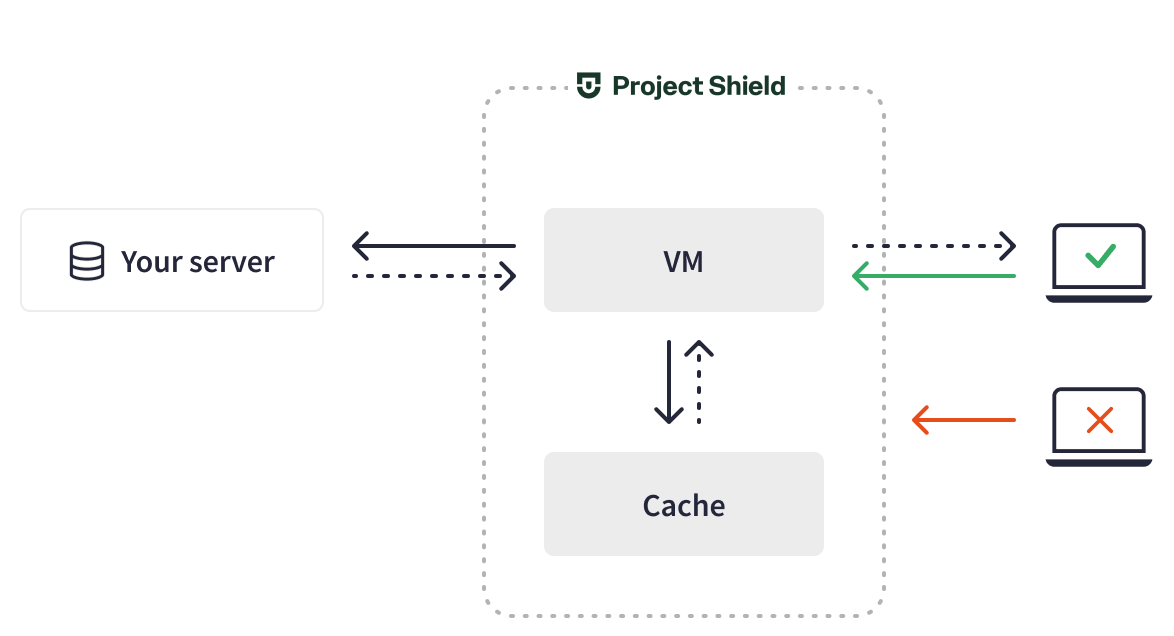 Project Shield Mechanism
Project Shield MechanismOriginally, Project Shield stored traffic logs in BigQuery. It used one large query to produce analytics and charts with different traffic metrics, such as the amount of traffic, QPS, the share of cached traffic, and the attack data. However, querying all of the logs, especially with dramatic spikes in traffic, was slow and expensive.
Often people want to know traffic metrics during critical times: if their website is under attack: they want to see what's happening right now. We need the data points to appear on the UI fast.
Project Shield’s team then added Firestore as an intermediate step, running a cron every minute to query logs from BigQuery and write the interim reports to Firestore, then using these reports to build charts. This step improved performance slightly, but the gain was not sufficient to meet critical business timelines, and it didn’t provide adequate visibility into historical traffic for customers.
Unlike BigQuery, Firestore was designed for medium-sized workloads. Therefore, it wasn’t possible to fetch many models at the same time to provide customers with cumulative statistics for extended time frames. Querying the logs every minute was inefficient from a cost perspective. In addition, some of the logs were coming to BigQuery with a delay, and it was necessary to run the cron again in 24 hours to double-check for the late-coming logs.
Querying over all of our traffic logs every minute is very expensive, especially when you consider that we are a DDoS defense service - the number of logs that we see can often spike dramatically.
Project Shield’s team looked for a data processing framework that would minimize end-to-end latency, meet their scaling needs for better customer visibility, and ensure cost efficiency.
They selected Apache Beam for its strong processing guarantees, streaming capabilities, and out-of-the-box I/Os for BigQuery and Pub/Sub. By pairing Apache Beam with the Dataflow runner, they also benefited from built-in autoscaling. In addition, the Apache Beam Python SDK lets you use Python across the board and simplifies reading data model types that have to be the same on the backend that consumes them and on the pipeline that writes them.
Use Cases
Project Shield became one of the early adopters of Apache Beam and migrated their workflows to streaming Apache Beam pipelines in 2020. Currently, Apache Beam powers multiple product needs with multiple streaming pipelines.
The unified streaming pipeline that produces user-facing analytics reads the logs from Pub/Sub while they arrive from Cloud Logging, windows logs per minute every minute, splits by the hostname of the request, generates reports, and writes the reports to BigQuery. The pipeline aggregates log data, removes Personally Identifiable Information (PII) without using a DLP, and allows for storing the data in BigQuery for a longer period while meeting the regulatory requirements. CombineFn allows Project Shield’s team to create a custom accumulator that takes the key into account when keying log data off the hostname and minute, combining the log data per key. If logs come in late, Apache Beam creates a new report and aggregates several reports per hostname per minute.
The fact that we can just key data, use CombinePerKey, and the accumulator works like magic was a big win for us
The Apache Beam log processing pipeline provides Project Shield with the ability to query only the relevant reports, thus enabling Project Shield to load the data to the customer dashboard within just 2 minutes. The pipeline also provides enhanced visibility for Project Shield’s customers, because the queried reports are much smaller in size and easier to store than the traffic logs.
The end-to-end pipeline latency was very meaningful to us, and the Apache Beam streaming allowed for displaying all the traffic metrics on charts within 2 minutes, but also to look back on days, weeks, or months of data and show graphs on a scalable timeframe to customers.

Project Shield extended the streaming Apache Beam log processing pipeline to generate a different type of report based on the logs and requests during attacks. The Apache Beam pipeline analyzes attacks and generates critical defense recommendations. These recommendations are then used by the internal long-term attack analysis system to fine-tune Project Shield’s defenses.
Apache Beam also powers Project Shield’s traffic rate-limiting decisions by analyzing patterns in the traffic logs. The streaming Apache Beam pipeline gathers information about the legitimate usage of a website, excludes abusive traffic from that analysis, and crafts traffic rate limits that divide the two groups safely. Those limits are then enforced in the form of Cloud Armor rules and policies and used to restrict abusive traffic or to ban it entirely.
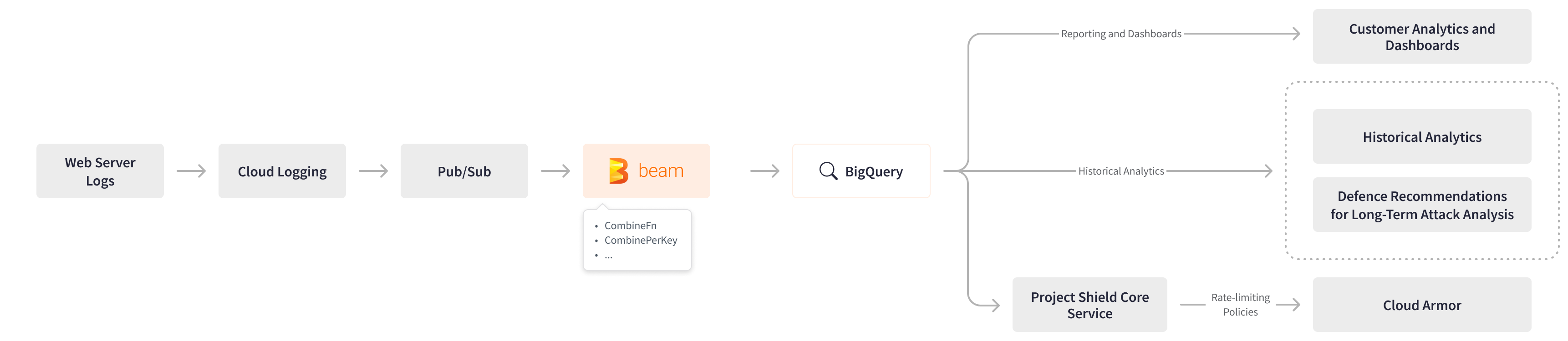 Apache Beam Streaming Log Analytics
Apache Beam Streaming Log AnalyticsThe combination of Apache Beam and Cloud Dataflow greatly simplifies Project Shield’s operational management of streaming pipelines. Apache Beam provides easy-to-use streaming primitives, while Dataflow enables out-of-the-box pipeline lifecycle management and compliments Pub/Sub’s delivery model with message deduplication and exactly-once, in-order processing. The Apache Beam Pub/Sub I/O provides the ability to key log data off Pub/Sub event timestamps. This feature enables Project Shield to improve the overall data accuracy by windowing log data after all the relevant logs come in. Various options for managing the pipeline lifecycle allow Project Shield to employ simple and reliable deployment processes. The Apache Beam Dataflow runner’s autoscaling and managed service capabilities help handle dramatic spikes in resource consumption during DDoS attacks and provide instant visibility for customers.
When attacks come in, we are ready to handle high volumes of traffic and deliver on-time metrics during critical windows with Apache Beam.
Results
The adoption of Apache Beam enabled Project Shield to embrace streaming, scale its pipelines, maximize efficiency, and minimize latency. The streaming Apache Beam pipelines process about 3 TB of log data daily at significantly over 10,000 queries per second to produce user-facing analytics, tailored traffic rate limits, and defense recommendations for over 3K customers all over the world. The streaming processing and powerful transforms of Apache Beam ensure delivery of critical metrics within just 2 minutes, enabling customer visibility into historical traffic, and resulting in a 91% compute efficiency gain, compared to the original solution.
The Apache Beam model and the autoscaling capabilities of its Dataflow runner help prevent the spikes in traffic during DDoS attacks from having a meaningful impact on our platform from an efficiency and financial perspective.
The Apache Beam data processing framework supports Project Shield’s goal to eliminate the DDoS attack as a weapon for silencing the voices of journalists and others who speak the truth, making the web a safer place.
Was this information useful?