




“Intuit Credit Karma is a financial management platform that aims to propel its more than 140 million members forward wherever they are on their financial journey by leveraging data and AI to connect the dots on their finances. ”

Credit Karma: Leveraging Apache Beam for Enhanced Financial Insights
Background
Credit Karma is a personal finance technology company that powers financial progress for its more than 140 million members through personalized insights and recommendations. Credit Karma uses data and AI platforms to create complex machine learning models that provide real-time insights so its members can make more informed financial decisions. The company uses Apache Beam to transform raw data into intelligent insights to power machine learning models.
Journey to Apache Beam
Credit Karma’s previous system, which used in-house Akka streams and Kubernetes-powered tools, was insufficient for our current needs. Specifically, it lacked the ability to:
- Intelligently partition real-time data streams into windows for analysis and transformation.
- Maintain state at low cost and complexity to enable fraud detection in money transactions.
- Reduce overall development time to speed up delivery of solutions for our data science stakeholders.
Apache Beam was chosen to address these shortcomings and provide the necessary capabilities.
Use Cases
Credit Karma leverages Apache Beam to address a broad spectrum of data processing requirements, particularly real-time data transformation to bolster machine learning models. Key applications include:
- preprocessing data and constructing graphs for live model scoring,
- large-scale ETL (Extract, Transform, Load) operations for analytics, and
- real-time aggregation of features to furnish near-instantaneous insights to models
The real-time aggregation of features is particularly crucial for fraud prevention, where metrics like average spending over time or transaction frequency can be strong indicators of fraudulent activity. Apache Beam’s capabilities - including windowing (analyzing data streams over sliding time windows), stateful processing (maintaining state information across data elements), and triggers (enabling actions based on specific conditions within the data stream) - allow Credit Karma to satisfy the stringent demands of real-time data processing. These demands encompass low latency data ingestion, sub-10ms end-to-end latency, and self-service feature creation for data scientists.
These requirements were challenging to achieve with Credit Karma’s previous infrastructure. By adopting Apache Beam in conjunction with Google Cloud Dataflow (a fully managed service for running Apache Beam pipelines), Credit Karma has not only simplified and accelerated the development of real-time features but also drastically reduced time to market. This empowers Credit Karma to rapidly iterate and innovate in critical areas like fraud detection, ultimately enhancing the customer experience.
*** A Use Case in Focus: Aggregated Features for Fraud Detection**
In one specific use case, Credit Karma implemented a unique aggregation strategy that differed from traditional streaming systems, which typically operate on either event-driven or timer-driven triggers. The use case required both types of triggers to operate simultaneously. Event-driven triggers generated aggregated features, stored in live databases for model scoring engines. Meanwhile, timer-driven triggers managed the expiration and removal of these features - all within the same job.
Apache Beam here processes approximately millions of transactions per day, primarily structured data, with a data size of ~100GB per day. The streaming data pipeline, with both event-based and timer-based triggers, and states, sources data from BigQuery and PubSub, and sinks it into BigQuery, Spanner, PubSub, and Firestore. Additionally, de-identified data is used for feature creation.
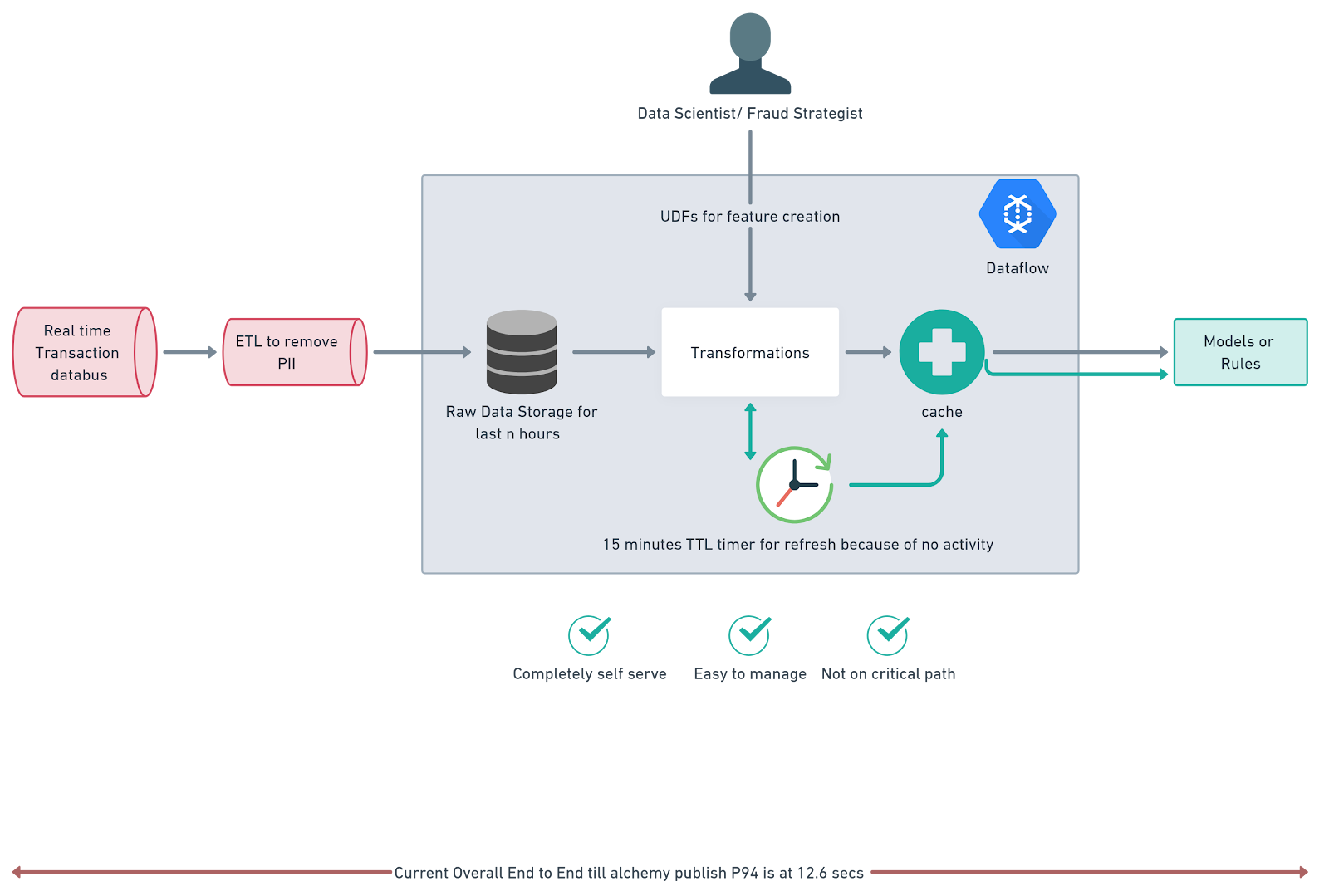
*Advantages of Using Dataflow for this Use Case
- Simple Setup: Easy to implement within the CK environment due to extensive use of GCP.
- High-Performing Streaming Engine: Research suggests Dataflow’s streaming engine outperforms Spark’s structured streaming and rivals Flink, the open-source standard for streaming applications.
- Non-Critical Path: Aggregations are computed offline and asynchronously, keeping Dataflow off the critical path for transaction completeness.
- Minimal Maintenance: As a Google-managed service, Dataflow doesn’t require significant team upkeep.
- Built-In Monitoring: Comes with pre-built monitoring dashboards and alerting systems via cloud monitoring and logging.
- Integrated State Storage: Dataflow’s streaming engine utilizes BigTable for state storage, eliminating the need for external state management and on-call responsibilities.
- Easy Updates: Established guidelines allow for updating existing Dataflow jobs without data loss, given backward-compatible schemas.
- Straightforward Backfilling: Computed data is pushed into BQ, and the service can be lifted and replayed on any BQ table, simplifying data backfilling (though speed is untested).
Future Work
To enhance the member experience and provide more relevant insights into their financial journey, we propose to modify the existing Credit Karma application use case.
Behavioral interaction events are generally high in traffic volume, eliminating the need for computation refresh at regular intervals. Hence, we plan to leverage the same technology, with the exception of the timer, to enable real-time calculation and delivery of application interaction intelligence. This will allow us to deliver personalized content and experiences to the member, leading to greater engagement and improved financial outcomes.
Results
By using Apache Beam, Credit Karma has achieved significant improvements, including:
- Reduced alerts and on-call duties
- Enabled machine learning on streaming data
- Connected a third-party service to tokenize client data
- Improved flexibility and pluggability
- Infrastructure cost optimization: Although costly, the solution was reliable for this use case.
- Faster time-to-value: Delivered a working solution in one quarter with 1 engineer, compared to the original estimate of 3 team members and two quarters.
Credit Karma’s tech stack includes DataflowRunner, Google Cloud Platform (GCP), and custom containers. Their teams use Java and Python for programming.
Was this information useful?