



blog
2017/08/28
Timely (and Stateful) Processing with Apache BeamKenneth Knowles [@KennKnowles]
In a prior blog post, I introduced the basics of stateful processing in Apache Beam, focusing on the addition of state to per-element processing. So-called timely processing complements stateful processing in Beam by letting you set timers to request a (stateful) callback at some point in the future.
What can you do with timers in Beam? Here are some examples:
- You can output data buffered in state after some amount of processing time.
- You can take special action when the watermark estimates that you have received all data up to a specified point in event time.
- You can author workflows with timeouts that alter state and emit output in response to the absence of additional input for some period of time.
These are just a few possibilities. State and timers together form a powerful programming paradigm for fine-grained control to express a huge variety of workflows. Stateful and timely processing in Beam is portable across data processing engines and integrated with Beam’s unified model of event time windowing in both streaming and batch processing.
What is stateful and timely processing?
In my prior post, I developed an understanding of stateful processing largely by contrast with associative, commutative combiners. In this post, I’ll emphasize a perspective that I had mentioned only briefly: that elementwise processing with access to per-key-and-window state and timers represents a fundamental pattern for “embarrassingly parallel” computation, distinct from the others in Beam.
In fact, stateful and timely computation is the low-level computational pattern that underlies the others. Precisely because it is lower level, it allows you to really micromanage your computations to unlock new use cases and new efficiencies. This incurs the complexity of manually managing your state and timers - it isn’t magic! Let’s first look again at the two primary computational patterns in Beam.
Element-wise processing (ParDo, Map, etc)
The most elementary embarrassingly parallel pattern is just using a bunch of
computers to apply the same function to every input element of a massive
collection. In Beam, per-element processing like this is expressed as a basic
ParDo - analogous to “Map” from MapReduce - which is like an enhanced “map”,
“flatMap”, etc, from functional programming.
The following diagram illustrates per-element processing. Input elements are squares, output elements are triangles. The colors of the elements represent their key, which will matter later. Each input element maps to the corresponding output element(s) completely independently. Processing may be distributed across computers in any way, yielding essentially limitless parallelism.
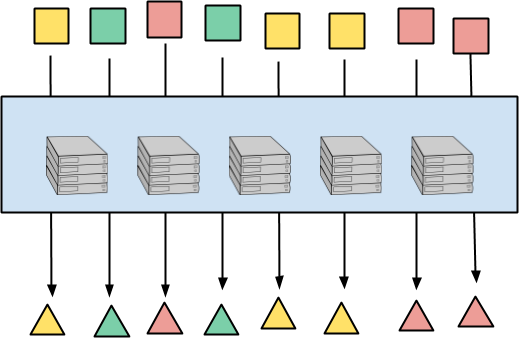
This pattern is obvious, exists in all data-parallel paradigms, and has a simple stateless implementation. Every input element can be processed independently or in arbitrary bundles. Balancing the work between computers is actually the hard part, and can be addressed by splitting, progress estimation, work-stealing, etc.
Per-key (and window) aggregation (Combine, Reduce, GroupByKey, etc.)
The other embarassingly parallel design pattern at the heart of Beam is per-key
(and window) aggregation. Elements sharing a key are colocated and then
combined using some associative and commutative operator. In Beam this is
expressed as a GroupByKey or Combine.perKey, and corresponds to the shuffle
and “Reduce” from MapReduce. It is sometimes helpful to think of per-key
Combine as the fundamental operation, and raw GroupByKey as a combiner that
just concatenates input elements. The communication pattern for the input
elements is the same, modulo some optimizations possible for Combine.
In the illustration here, recall that the color of each element represents the key. So all of the red squares are routed to the same location where they are aggregated and the red triangle is the output. Likewise for the yellow and green squares, etc. In a real application, you may have millions of keys, so the parallelism is still massive.
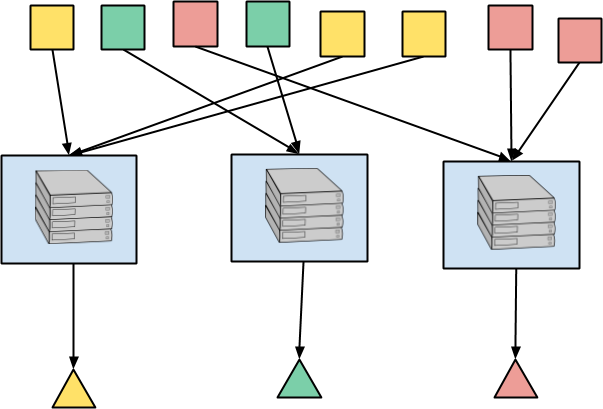
The underlying data processing engine will, at some level of abstraction, use state to perform this aggregation across all the elements arriving for a key. In particular, in a streaming execution, the aggregation process may need to wait for more data to arrive or for the watermark to estimate that all input for an event time window is complete. This requires some way to store the intermediate aggregation between input elements as well a way to a receive a callback when it is time to emit the result. As a result, the execution of per key aggregation by a stream processing engine fundamentally involves state and timers.
However, your code is just a declarative expression of the aggregation operator. The runner can choose a variety of ways to execute your operator. I went over this in detail in my prior post focused on state alone. Since you do not observe elements in any defined order, nor manipulate mutable state or timers directly, I call this neither stateful nor timely processing.
Per-key-and-window stateful, timely processing
Both ParDo and Combine.perKey are standard patterns for parallelism that go
back decades. When implementing these in a massive-scale distributed data
processing engine, we can highlight a few characteristics that are particularly
important.
Let us consider these characteristics of ParDo:
- You write single-threaded code to process one element.
- Elements are processed in arbitrary order with no dependencies or interaction between processing of elements.
And these characteristics for Combine.perKey:
- Elements for a common key and window are gathered together.
- A user-defined operator is applied to those elements.
Combining some of the characteristics of unrestricted parallel mapping and per-key-and-window combination, we can discern a megaprimitive from which we build stateful and timely processing:
- Elements for a common key and window are gathered together.
- Elements are processed in arbitrary order.
- You write single-threaded code to process one element or timer, possibly accessing state or setting timers.
In the illustration below, the red squares are gathered and fed one by one to
the stateful, timely, DoFn. As each element is processed, the DoFn has
access to state (the color-partitioned cylinder on the right) and can set
timers to receive callbacks (the colorful clocks on the left).
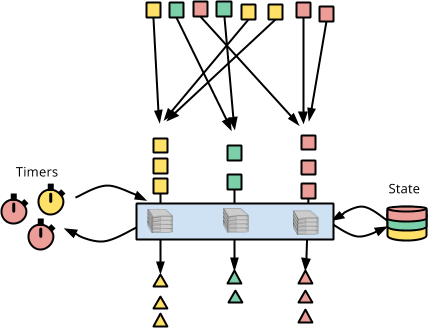
So that is the abstract notion of per-key-and-window stateful, timely processing in Apache Beam. Now let’s see what it looks like to write code that accesses state, sets timers, and receives callbacks.
Example: Batched RPC
To demonstrate stateful and timely processing, let’s work through a concrete example, with code.
Suppose you are writing a system to analyze events. You have a ton of data coming in and you need to enrich each event by RPC to an external system. You can’t just issue an RPC per event. Not only would this be terrible for performance, but it would also likely blow your quota with the external system. So you’d like to gather a number of events, make one RPC for them all, and then output all the enriched events.
State
Let’s set up the state we need to track batches of elements. As each element comes in, we will write the element to a buffer while tracking the number of elements we have buffered. Here are the state cells in code:
new DoFn<Event, EnrichedEvent>() {
@StateId("buffer")
private final StateSpec<BagState<Event>> bufferedEvents = StateSpecs.bag();
@StateId("count")
private final StateSpec<ValueState<Integer>> countState = StateSpecs.value();
… TBD …
}class StatefulBufferingFn(beam.DoFn):
BUFFER_STATE = BagStateSpec('buffer', EventCoder())
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(),
combiners.SumCombineFn())Walking through the code, we have:
- The state cell
"buffer"is an unordered bag of buffered events. - The state cell
"count"tracks how many events have been buffered.
Next, as a recap of reading and writing state, let’s write our @ProcessElement
method. We will choose a limit on the size of the buffer, MAX_BUFFER_SIZE. If
our buffer reaches this size, we will perform a single RPC to enrich all the
events, and output.
new DoFn<Event, EnrichedEvent>() {
private static final int MAX_BUFFER_SIZE = 500;
@StateId("buffer")
private final StateSpec<BagState<Event>> bufferedEvents = StateSpecs.bag();
@StateId("count")
private final StateSpec<ValueState<Integer>> countState = StateSpecs.value();
@ProcessElement
public void process(
ProcessContext context,
@StateId("buffer") BagState<Event> bufferState,
@StateId("count") ValueState<Integer> countState) {
int count = firstNonNull(countState.read(), 0);
count = count + 1;
countState.write(count);
bufferState.add(context.element());
if (count >= MAX_BUFFER_SIZE) {
for (EnrichedEvent enrichedEvent : enrichEvents(bufferState.read())) {
context.output(enrichedEvent);
}
bufferState.clear();
countState.clear();
}
}
… TBD …
}class StatefulBufferingFn(beam.DoFn):
MAX_BUFFER_SIZE = 500;
BUFFER_STATE = BagStateSpec('buffer', EventCoder())
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(),
combiners.SumCombineFn())
def process(self, element,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE)):
buffer_state.add(element)
count_state.add(1)
count = count_state.read()
if count >= MAX_BUFFER_SIZE:
for event in buffer_state.read():
yield event
count_state.clear()
buffer_state.clear()Here is an illustration to accompany the code:
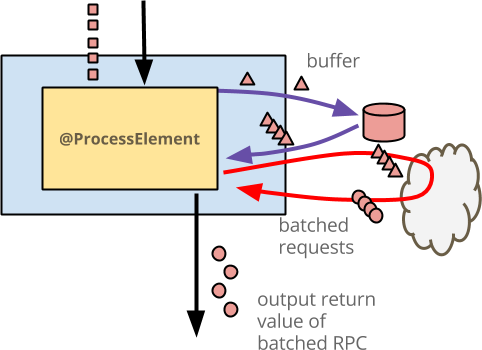
- The blue box is the
DoFn. - The yellow box within it is the
@ProcessElementmethod. - Each input event is a red square - this diagram just shows the activity for
a single key, represented by the color red. Your
DoFnwill run the same workflow in parallel for all keys which are perhaps user IDs. - Each input event is written to the buffer as a red triangle, representing the fact that you might actually buffer more than just the raw input, even though this code doesn’t.
- The external service is drawn as a cloud. When there are enough buffered
events, the
@ProcessElementmethod reads the events from state and issues a single RPC. - Each output enriched event is drawn as a red circle. To consumers of this output, it looks just like an element-wise operation.
So far, we have only used state, but not timers. You may have noticed that there is a problem - there will usually be data left in the buffer. If no more input arrives, that data will never be processed. In Beam, every window has some point in event time when any further input for the window is considered too late and is discarded. At this point, we say that the window has “expired”. Since no further input can arrive to access the state for that window, the state is also discarded. For our example, we need to ensure that all leftover events are output when the window expires.
Event Time Timers
An event time timer requests a call back when the watermark for an input
PCollection reaches some threshold. In other words, you can use an event time
timer to take action at a specific moment in event time - a particular point of
completeness for a PCollection - such as when a window expires.
For our example, let us add an event time timer so that when the window expires, any events remaining in the buffer are processed.
new DoFn<Event, EnrichedEvent>() {
…
@TimerId("expiry")
private final TimerSpec expirySpec = TimerSpecs.timer(TimeDomain.EVENT_TIME);
@ProcessElement
public void process(
ProcessContext context,
BoundedWindow window,
@StateId("buffer") BagState<Event> bufferState,
@StateId("count") ValueState<Integer> countState,
@TimerId("expiry") Timer expiryTimer) {
expiryTimer.set(window.maxTimestamp().plus(allowedLateness));
… same logic as above …
}
@OnTimer("expiry")
public void onExpiry(
OnTimerContext context,
@StateId("buffer") BagState<Event> bufferState) {
if (!bufferState.isEmpty().read()) {
for (EnrichedEvent enrichedEvent : enrichEvents(bufferState.read())) {
context.output(enrichedEvent);
}
bufferState.clear();
}
}
}class StatefulBufferingFn(beam.DoFn):
…
EXPIRY_TIMER = TimerSpec('expiry', TimeDomain.WATERMARK)
def process(self, element,
w=beam.DoFn.WindowParam,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE),
expiry_timer=beam.DoFn.TimerParam(EXPIRY_TIMER)):
expiry_timer.set(w.end + ALLOWED_LATENESS)
… same logic as above …
@on_timer(EXPIRY_TIMER)
def expiry(self,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE)):
events = buffer_state.read()
for event in events:
yield event
buffer_state.clear()
count_state.clear()Let’s unpack the pieces of this snippet:
We declare an event time timer with
@TimerId("expiry"). We will use the identifier"expiry"to identify the timer for setting the callback time as well as receiving the callback.The variable
expiryTimer, annotated with@TimerId, is set to the valueTimerSpecs.timer(TimeDomain.EVENT_TIME), indicating that we want a callback according to the event time watermark of the input elements.In the
@ProcessElementelement we annotate a parameter@TimerId("expiry") Timer. The Beam runner automatically provides thisTimerparameter by which we can set (and reset) the timer. It is inexpensive to reset a timer repeatedly, so we simply set it on every element.We define the
onExpirymethod, annotated with@OnTimer("expiry"), that performs a final event enrichment RPC and outputs the result. The Beam runner delivers the callback to this method by matching its identifier.
Illustrating this logic, we have the diagram below:
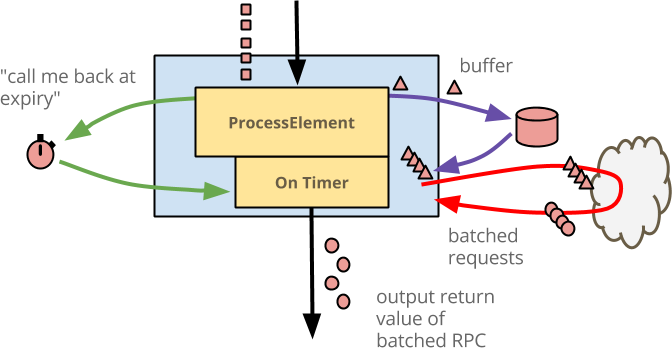
Both the @ProcessElement and @OnTimer("expiry") methods perform the same
access to buffered state, perform the same batched RPC, and output enriched
elements.
Now, if we are executing this in a streaming real-time manner, we might still have unbounded latency for particular buffered data. If the watermark is advancing very slowly, or event time windows are chosen to be quite large, then a lot of time might pass before output is emitted based either on enough elements or window expiration. We can also use timers to limit the amount of wall-clock time, aka processing time, before we process buffered elements. We can choose some reasonable amount of time so that even though we are issuing RPCs that are not as large as they might be, it is still few enough RPCs to avoid blowing our quota with the external service.
Processing Time Timers
A timer in processing time (time as it passes while your pipeline is executing) is intuitively simple: you want to wait a certain amount of time and then receive a call back.
To put the finishing touches on our example, we will set a processing time
timer as soon as any data is buffered. Note that we set the timer only when
the current buffer is empty, so that we don’t continually reset the timer.
When the first element arrives, we set the timer for the current moment plus
MAX_BUFFER_DURATION. After the allotted processing time has passed, a
callback will fire and enrich and emit any buffered elements.
new DoFn<Event, EnrichedEvent>() {
…
private static final Duration MAX_BUFFER_DURATION = Duration.standardSeconds(1);
@TimerId("stale")
private final TimerSpec staleSpec = TimerSpecs.timer(TimeDomain.PROCESSING_TIME);
@ProcessElement
public void process(
ProcessContext context,
BoundedWindow window,
@StateId("count") ValueState<Integer> countState,
@StateId("buffer") BagState<Event> bufferState,
@TimerId("stale") Timer staleTimer,
@TimerId("expiry") Timer expiryTimer) {
if (firstNonNull(countState.read(), 0) == 0) {
staleTimer.offset(MAX_BUFFER_DURATION).setRelative();
}
… same processing logic as above …
}
@OnTimer("stale")
public void onStale(
OnTimerContext context,
@StateId("buffer") BagState<Event> bufferState,
@StateId("count") ValueState<Integer> countState) {
if (!bufferState.isEmpty().read()) {
for (EnrichedEvent enrichedEvent : enrichEvents(bufferState.read())) {
context.output(enrichedEvent);
}
bufferState.clear();
countState.clear();
}
}
… same expiry as above …
}class StatefulBufferingFn(beam.DoFn):
…
STALE_TIMER = TimerSpec('stale', TimeDomain.REAL_TIME)
MAX_BUFFER_DURATION = 1
def process(self, element,
w=beam.DoFn.WindowParam,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE),
expiry_timer=beam.DoFn.TimerParam(EXPIRY_TIMER),
stale_timer=beam.DoFn.TimerParam(STALE_TIMER)):
if count_state.read() == 0:
# We set an absolute timestamp here (not an offset like in the Java SDK)
stale_timer.set(time.time() + StatefulBufferingFn.MAX_BUFFER_DURATION)
… same logic as above …
@on_timer(STALE_TIMER)
def stale(self,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE)):
events = buffer_state.read()
for event in events:
yield event
buffer_state.clear()
count_state.clear()Here is an illustration of the final code:
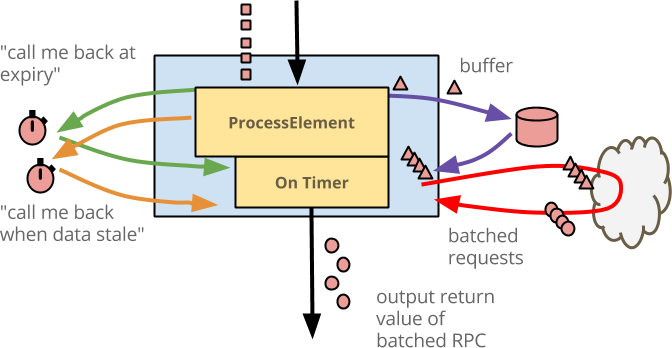
Recapping the entirety of the logic:
- As events arrive at
@ProcessElementthey are buffered in state. - If the size of the buffer exceeds a maximum, the events are enriched and output.
- If the buffer fills too slowly and the events get stale before the maximum is reached, a timer causes a callback which enriches the buffered events and outputs.
- Finally, as any window is expiring, any events buffered in that window are processed and output prior to the state for that window being discarded.
In the end, we have a full example that uses state and timers to explicitly
manage the low-level details of a performance-sensitive transform in Beam. As
we added more and more features, our DoFn actually became pretty large. That
is a normal characteristic of stateful, timely processing. You are really
digging in and managing a lot of details that are handled automatically when
you express your logic using Beam’s higher-level APIs. What you gain from this
extra effort is an ability to tackle use cases and achieve efficiencies that
may not have been possible otherwise.
State and Timers in Beam’s Unified Model
Beam’s unified model for event time across streaming and batch processing has
novel implications for state and timers. Usually, you don’t need to do anything
for your stateful and timely DoFn to work well in the Beam model. But it will
help to be aware of the considerations below, especially if you have used
similar features before outside of Beam.
Event Time Windowing “Just Works”
One of the raisons d’être for Beam is correct processing of out-of-order event data, which is almost all event data. Beam’s solution to out-of-order data is event time windowing, where windows in event time yield correct results no matter what windowing a user chooses or what order the events come in.
If you write a stateful, timely transform, it should work no matter how the surrounding pipeline chooses to window event time. If the pipeline chooses fixed windows of one hour (sometimes called tumbling windows) or windows of 30 minutes sliding by 10 minutes, the stateful, timely transform should transparently work correctly.
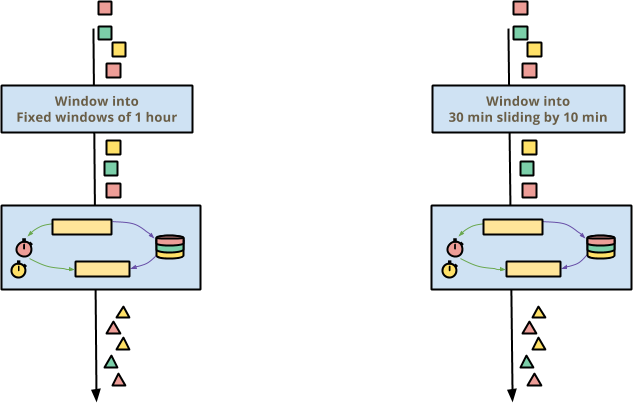
This works in Beam automatically, because state and timers are partitioned per key and window. Within each key and window, the stateful, timely processing is essentially independent. As an added benefit, the passing of event time (aka advancement of the watermark) allows automatic release of unreachable state when a window expires, so you often don’t have to worry about evicting old state.
Unified real-time and historical processing
A second tenet of Beam’s semantic model is that processing must be unified between batch and streaming. One important use case for this unification is the ability to apply the same logic to a stream of events in real time and to archived storage of the same events.
A common characteristic of archived data is that it may arrive radically out of order. The sharding of archived files often results in a totally different ordering for processing than events coming in near-real-time. The data will also all be all available and hence delivered instantaneously from the point of view of your pipeline. Whether running experiments on past data or reprocessing past results to fix a data processing bug, it is critically important that your processing logic be applicable to archived events just as easily as incoming near-real-time data.
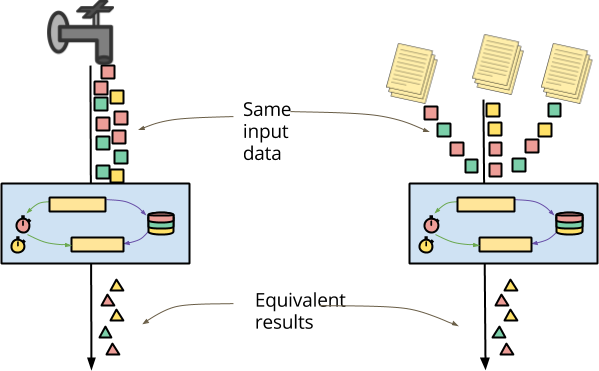
It is (deliberately) possible to write a stateful and timely DoFn that delivers
results that depend on ordering or delivery timing, so in this sense there is
additional burden on you, the DoFn author, to ensure that this nondeterminism
falls within documented allowances.
Go use it!
I’ll end this post in the same way I ended the last. I hope you will go try out Beam with stateful, timely processing. If it opens up new possibilities for you, then great! If not, we want to hear about it. Since this is a new feature, please check the capability matrix to see the level of support for your preferred Beam backend(s).
And please do join the Beam community at user@beam.apache.org and follow @ApacheBeam on Twitter.