



blog
2024/06/20
Deploy Python pipelines on Kubernetes using the Flink runnerJaehyeon Kim
Deploy Python pipelines on Kubernetes using the Flink runner
The Apache Flink Kubernetes Operator acts as a control plane to manage the complete deployment lifecycle of Apache Flink applications. With the operator, we can simplify the deployment and management of Apache Beam pipelines.
In this post, we develop an Apache Beam pipeline using the Python SDK and deploy it on an Apache Flink cluster by using the Apache Flink runner. We first deploy an Apache Kafka cluster on a minikube cluster, because the pipeline uses Kafka topics for its data source and sink. Then, we develop the pipeline as a Python package and add the package to a custom Docker image so that Python user code can be executed externally. For deployment, we create a Flink session cluster using the Flink Kubernetes Operator, and deploy the pipeline using a Kubernetes job. Finally, we check the output of the application by sending messages to the input Kafka topic using a Python producer application.
Resources to run a Python Beam pipeline on Flink
We develop an Apache Beam pipeline using the Python SDK and deploy it on an Apache Flink cluster using the Apache Flink runner. Although the Flink cluster is created by the Flink Kubernetes Operator, we need two components to run the pipeline on the Flink runner: the job service and the SDK harness. Roughly speaking, the job service converts details about a Python pipeline into a format that the Flink runner can understand. The SDK harness executes the Python user code. The Python SDK provides convenience wrappers to manage those components, and you can use it by specifying FlinkRunner in the pipeline option, for example, --runner=FlinkRunner. The job service is managed automatically. We rely on our own SDK harness as a sidecar container for simplicity. Also, we need the Java IO Expansion Service, because the pipeline uses Apache Kafka topics for its data source and sink, and the Kafka Connector I/O is developed in Java. Simply put, the expansion service is used to serialize data for the Java SDK.
Set up the Kafka cluster
An Apache Kafka cluster is deployed using the Strimzi Operator on a minikube cluster. We install Strimzi version 0.39.0 and Kubernetes version 1.25.3. After the minikube CLI and Docker are installed, you can create a minikube cluster by specifying the Kubernetes version. You can find the source code for this blog post in the GitHub repository.
minikube start --cpus='max' --memory=20480 \
--addons=metrics-server --kubernetes-version=v1.25.3Deploy the Strimzi operator
The GitHub repository keeps manifest files that you can use to deploy the Strimzi operator, Kafka cluster, and Kafka management application. To download a different version of the operator, download the relevant manifest file by specifying the version. By default, the manifest file assumes that the resources are deployed in the myproject namespace. However, because we deploy them in the default namespace, we need to change the resource namespace. We change the resource namespace using sed.
To deploy the operator, use the kubectl create command.
## Download and deploy the Strimzi operator.
STRIMZI_VERSION="0.39.0"
## Optional: If downloading a different version, include this step.
DOWNLOAD_URL=https://github.com/strimzi/strimzi-kafka-operator/releases/download/$STRIMZI_VERSION/strimzi-cluster-operator-$STRIMZI_VERSION.yaml
curl -L -o kafka/manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml \
${DOWNLOAD_URL}
# Update the namespace from myproject to default.
sed -i 's/namespace: .*/namespace: default/' kafka/manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml
## Deploy the Strimzi cluster operator.
kubectl create -f kafka/manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yamlVerify that the Strimzi Operator runs as a Kubernetes deployment.
kubectl get deploy,rs,po
# NAME READY UP-TO-DATE AVAILABLE AGE
# deployment.apps/strimzi-cluster-operator 1/1 1 1 2m50s
# NAME DESIRED CURRENT READY AGE
# replicaset.apps/strimzi-cluster-operator-8d6d4795c 1 1 1 2m50s
# NAME READY STATUS RESTARTS AGE
# pod/strimzi-cluster-operator-8d6d4795c-94t8c 1/1 Running 0 2m49sDeploy the Kafka cluster
We deploy a Kafka cluster with a single broker and Zookeeper node. It has both internal and external listeners on ports 9092 and 29092, respectively. The external listener is used to access the Kafka cluster outside the minikube cluster. Also, the cluster is configured to allow automatic creation of topics (auto.create.topics.enable: "true"), and the default number of partitions is set to 3 (num.partitions: 3).
# kafka/manifests/kafka-cluster.yaml
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: demo-cluster
spec:
kafka:
version: 3.5.2
replicas: 1
resources:
requests:
memory: 256Mi
cpu: 250m
limits:
memory: 512Mi
cpu: 500m
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: external
port: 29092
type: nodeport
tls: false
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 20Gi
deleteClaim: true
config:
offsets.topic.replication.factor: 1
transaction.state.log.replication.factor: 1
transaction.state.log.min.isr: 1
default.replication.factor: 1
min.insync.replicas: 1
inter.broker.protocol.version: "3.5"
auto.create.topics.enable: "true"
num.partitions: 3
zookeeper:
replicas: 1
resources:
requests:
memory: 256Mi
cpu: 250m
limits:
memory: 512Mi
cpu: 500m
storage:
type: persistent-claim
size: 10Gi
deleteClaim: true
Deploy he Kafka cluster using the kubectl create command.
kubectl create -f kafka/manifests/kafka-cluster.yamlThe Kafka and Zookeeper nodes are managed by the StrimziPodSet custom resource. It also creates multiple Kubernetes services. In this series, we use the following services:
- communication within the Kubernetes cluster
demo-cluster-kafka-bootstrap- to access Kafka brokers from the client and management appsdemo-cluster-zookeeper-client- to access Zookeeper node from the management app
- communication from the host
demo-cluster-kafka-external-bootstrap- to access Kafka brokers from the producer app
kubectl get po,strimzipodsets.core.strimzi.io,svc -l app.kubernetes.io/instance=demo-cluster
# NAME READY STATUS RESTARTS AGE
# pod/demo-cluster-kafka-0 1/1 Running 0 115s
# pod/demo-cluster-zookeeper-0 1/1 Running 0 2m20s
# NAME PODS READY PODS CURRENT PODS AGE
# strimzipodset.core.strimzi.io/demo-cluster-kafka 1 1 1 115s
# strimzipodset.core.strimzi.io/demo-cluster-zookeeper 1 1 1 2m20s
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# service/demo-cluster-kafka-bootstrap ClusterIP 10.101.175.64 <none> 9091/TCP,9092/TCP 115s
# service/demo-cluster-kafka-brokers ClusterIP None <none> 9090/TCP,9091/TCP,8443/TCP,9092/TCP 115s
# service/demo-cluster-kafka-external-0 NodePort 10.106.155.20 <none> 29092:32475/TCP 115s
# service/demo-cluster-kafka-external-bootstrap NodePort 10.111.244.128 <none> 29092:32674/TCP 115s
# service/demo-cluster-zookeeper-client ClusterIP 10.100.215.29 <none> 2181/TCP 2m20s
# service/demo-cluster-zookeeper-nodes ClusterIP None <none> 2181/TCP,2888/TCP,3888/TCP 2m20sDeploy the Kafka UI
UI for Apache Kafka (kafka-ui) is a free and open-source Kafka management application. It’s deployed as a Kubernetes Deployment. The Deployment is configured to have a single instance, and the Kafka cluster access details are specified as environment variables.
# kafka/manifests/kafka-ui.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: kafka-ui
name: kafka-ui
spec:
type: ClusterIP
ports:
- port: 8080
targetPort: 8080
selector:
app: kafka-ui
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: kafka-ui
name: kafka-ui
spec:
replicas: 1
selector:
matchLabels:
app: kafka-ui
template:
metadata:
labels:
app: kafka-ui
spec:
containers:
- image: provectuslabs/kafka-ui:v0.7.1
name: kafka-ui-container
ports:
- containerPort: 8080
env:
- name: KAFKA_CLUSTERS_0_NAME
value: demo-cluster
- name: KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS
value: demo-cluster-kafka-bootstrap:9092
- name: KAFKA_CLUSTERS_0_ZOOKEEPER
value: demo-cluster-zookeeper-client:2181
resources:
requests:
memory: 256Mi
cpu: 250m
limits:
memory: 512Mi
cpu: 500m
Deploy the Kafka management app (kafka-ui) using the kubectl create command.
kubectl create -f kafka/manifests/kafka-ui.yaml
kubectl get all -l app=kafka-ui
# NAME READY STATUS RESTARTS AGE
# pod/kafka-ui-65dbbc98dc-zl5gv 1/1 Running 0 35s
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# service/kafka-ui ClusterIP 10.109.14.33 <none> 8080/TCP 36s
# NAME READY UP-TO-DATE AVAILABLE AGE
# deployment.apps/kafka-ui 1/1 1 1 35s
# NAME DESIRED CURRENT READY AGE
# replicaset.apps/kafka-ui-65dbbc98dc 1 1 1 35sWe use kubectl port-forward to connect to the kafka-ui server running in the minikube cluster on port 8080.
kubectl port-forward svc/kafka-ui 8080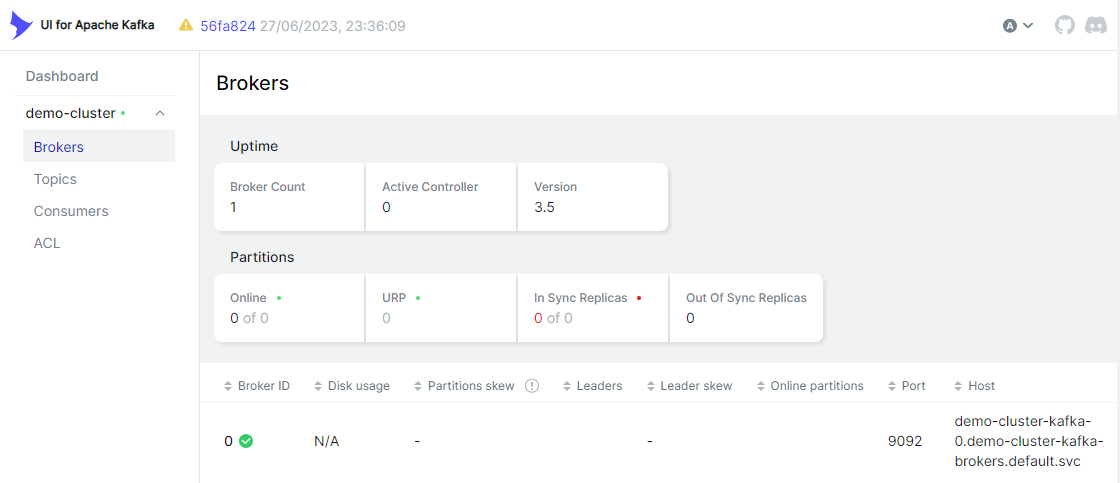
Develop a stream processing app
We develop an Apache Beam pipeline as a Python package and add it to a custom Docker image, which is used to execute Python user code (SDK harness). We also build another custom Docker image, which adds the Java SDK of Apache Beam to the official Flink base image. This image is used to deploy a Flink cluster and to execute Java user code of the Kafka Connector I/O.
Beam pipeline code
The application first reads text messages from an input Kafka topic. Next, it extracts words by splitting the messages (ReadWordsFromKafka). Then, the elements (words) are added to a fixed time window of 5 seconds, and their average length is calculated (CalculateAvgWordLen). Finally, we include the window start and end timestamps, and send the updated element to an output Kafka topic (WriteWordLenToKafka).
We create a custom Java IO Expansion Service (get_expansion_service) and add it to the ReadFromKafka and WriteToKafka transforms of the Kafka Connector I/O. Although the Kafka I/O provides a function to create that service, it did not work for me (or I do not understand how to make use of it yet). Instead, I created a custom service, as illustrated in Building Big Data Pipelines with Apache Beam by Jan Lukavský. The expansion service Jar file (beam-sdks-java-io-expansion-service.jar) must exist in the Kubernetes job that executes the pipeline, while the Java SDK (/opt/apache/beam/boot) must exist in the runner worker.
# beam/word_len/word_len.py
import json
import argparse
import re
import logging
import typing
import apache_beam as beam
from apache_beam import pvalue
from apache_beam.io import kafka
from apache_beam.transforms.window import FixedWindows
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.options.pipeline_options import SetupOptions
from apache_beam.transforms.external import JavaJarExpansionService
def get_expansion_service(
jar="/opt/apache/beam/jars/beam-sdks-java-io-expansion-service.jar", args=None
):
if args == None:
args = [
"--defaultEnvironmentType=PROCESS",
'--defaultEnvironmentConfig={"command": "/opt/apache/beam/boot"}',
"--experiments=use_deprecated_read",
]
return JavaJarExpansionService(jar, ["{{PORT}}"] + args)
class WordAccum(typing.NamedTuple):
length: int
count: int
beam.coders.registry.register_coder(WordAccum, beam.coders.RowCoder)
def decode_message(kafka_kv: tuple, verbose: bool = False):
if verbose:
print(kafka_kv)
return kafka_kv[1].decode("utf-8")
def tokenize(element: str):
return re.findall(r"[A-Za-z\']+", element)
def create_message(element: typing.Tuple[str, str, float]):
msg = json.dumps(dict(zip(["window_start", "window_end", "avg_len"], element)))
print(msg)
return "".encode("utf-8"), msg.encode("utf-8")
class AverageFn(beam.CombineFn):
def create_accumulator(self):
return WordAccum(length=0, count=0)
def add_input(self, mutable_accumulator: WordAccum, element: str):
length, count = tuple(mutable_accumulator)
return WordAccum(length=length + len(element), count=count + 1)
def merge_accumulators(self, accumulators: typing.List[WordAccum]):
lengths, counts = zip(*accumulators)
return WordAccum(length=sum(lengths), count=sum(counts))
def extract_output(self, accumulator: WordAccum):
length, count = tuple(accumulator)
return length / count if count else float("NaN")
def get_accumulator_coder(self):
return beam.coders.registry.get_coder(WordAccum)
class AddWindowTS(beam.DoFn):
def process(self, avg_len: float, win_param=beam.DoFn.WindowParam):
yield (
win_param.start.to_rfc3339(),
win_param.end.to_rfc3339(),
avg_len,
)
class ReadWordsFromKafka(beam.PTransform):
def __init__(
self,
bootstrap_servers: str,
topics: typing.List[str],
group_id: str,
verbose: bool = False,
expansion_service: typing.Any = None,
label: str | None = None,
) -> None:
super().__init__(label)
self.boostrap_servers = bootstrap_servers
self.topics = topics
self.group_id = group_id
self.verbose = verbose
self.expansion_service = expansion_service
def expand(self, input: pvalue.PBegin):
return (
input
| "ReadFromKafka"
>> kafka.ReadFromKafka(
consumer_config={
"bootstrap.servers": self.boostrap_servers,
"auto.offset.reset": "latest",
# "enable.auto.commit": "true",
"group.id": self.group_id,
},
topics=self.topics,
timestamp_policy=kafka.ReadFromKafka.create_time_policy,
commit_offset_in_finalize=True,
expansion_service=self.expansion_service,
)
| "DecodeMessage" >> beam.Map(decode_message)
| "Tokenize" >> beam.FlatMap(tokenize)
)
class CalculateAvgWordLen(beam.PTransform):
def expand(self, input: pvalue.PCollection):
return (
input
| "Windowing" >> beam.WindowInto(FixedWindows(size=5))
| "GetAvgWordLength" >> beam.CombineGlobally(AverageFn()).without_defaults()
)
class WriteWordLenToKafka(beam.PTransform):
def __init__(
self,
bootstrap_servers: str,
topic: str,
expansion_service: typing.Any = None,
label: str | None = None,
) -> None:
super().__init__(label)
self.boostrap_servers = bootstrap_servers
self.topic = topic
self.expansion_service = expansion_service
def expand(self, input: pvalue.PCollection):
return (
input
| "AddWindowTS" >> beam.ParDo(AddWindowTS())
| "CreateMessages"
>> beam.Map(create_message).with_output_types(typing.Tuple[bytes, bytes])
| "WriteToKafka"
>> kafka.WriteToKafka(
producer_config={"bootstrap.servers": self.boostrap_servers},
topic=self.topic,
expansion_service=self.expansion_service,
)
)
def run(argv=None, save_main_session=True):
parser = argparse.ArgumentParser(description="Beam pipeline arguments")
parser.add_argument(
"--deploy",
dest="deploy",
action="store_true",
default="Flag to indicate whether to deploy to a cluster",
)
parser.add_argument(
"--bootstrap_servers",
dest="bootstrap",
default="host.docker.internal:29092",
help="Kafka bootstrap server addresses",
)
parser.add_argument(
"--input_topic",
dest="input",
default="input-topic",
help="Kafka input topic name",
)
parser.add_argument(
"--output_topic",
dest="output",
default="output-topic-beam",
help="Kafka output topic name",
)
parser.add_argument(
"--group_id",
dest="group",
default="beam-word-len",
help="Kafka output group ID",
)
known_args, pipeline_args = parser.parse_known_args(argv)
print(known_args)
print(pipeline_args)
# We use the save_main_session option because one or more DoFn elements in this
# workflow rely on global context. That is, a module imported at the module level.
pipeline_options = PipelineOptions(pipeline_args)
pipeline_options.view_as(SetupOptions).save_main_session = save_main_session
expansion_service = None
if known_args.deploy is True:
expansion_service = get_expansion_service()
with beam.Pipeline(options=pipeline_options) as p:
(
p
| "ReadWordsFromKafka"
>> ReadWordsFromKafka(
bootstrap_servers=known_args.bootstrap,
topics=[known_args.input],
group_id=known_args.group,
expansion_service=expansion_service,
)
| "CalculateAvgWordLen" >> CalculateAvgWordLen()
| "WriteWordLenToKafka"
>> WriteWordLenToKafka(
bootstrap_servers=known_args.bootstrap,
topic=known_args.output,
expansion_service=expansion_service,
)
)
logging.getLogger().setLevel(logging.DEBUG)
logging.info("Building pipeline ...")
if __name__ == "__main__":
run()
The pipeline script is added to a Python package under a folder named word_len. A simple module named run is created, because it is executed as a module, for example, python -m .... When I ran the pipeline as a script, I encountered an error. This packaging method is for demonstration only. For a recommended way of packaging a pipeline, see Managing Python Pipeline Dependencies.
# beam/word_len/run.py
from . import *
run()
Overall, the pipeline package uses the following structure.
tree beam/word_len
beam/word_len
├── __init__.py
├── run.py
└── word_len.pyBuild Docker images
As discussed previously, we build a custom Docker image (beam-python-example:1.16) and use it to deploy a Flink cluster and to run the Java user code of the Kafka Connector I/O.
# beam/Dockerfile
FROM flink:1.16
COPY --from=apache/beam_java11_sdk:2.56.0 /opt/apache/beam/ /opt/apache/beam/
We also build a custom Docker image (beam-python-harness:2.56.0) to run Python user code (SDK harness). From the Python SDK Docker image, it first installs the Java Development Kit (JDK) and downloads the Java IO Expansion Service Jar file. Then, the Beam pipeline packages are copied to the /app folder. The app folder is added to the PYTHONPATH environment variable, which makes the packages searchable.
# beam/Dockerfile-python-harness
FROM apache/beam_python3.10_sdk:2.56.0
ARG BEAM_VERSION
ENV BEAM_VERSION=${BEAM_VERSION:-2.56.0}
ENV REPO_BASE_URL=https://repo1.maven.org/maven2/org/apache/beam
RUN apt-get update && apt-get install -y default-jdk
RUN mkdir -p /opt/apache/beam/jars \
&& wget ${REPO_BASE_URL}/beam-sdks-java-io-expansion-service/${BEAM_VERSION}/beam-sdks-java-io-expansion-service-${BEAM_VERSION}.jar \
--progress=bar:force:noscroll -O /opt/apache/beam/jars/beam-sdks-java-io-expansion-service.jar
COPY word_len /app/word_len
COPY word_count /app/word_count
ENV PYTHONPATH="$PYTHONPATH:/app"
Because the custom images need to be accessible in the minikube cluster, we point the terminal’s docker-cli to the minikube’s Docker engine. Then, we can build the images using the docker build command.
eval $(minikube docker-env)
docker build -t beam-python-example:1.16 beam/
docker build -t beam-python-harness:2.56.0 -f beam/Dockerfile-python-harness beam/Deploy the stream processing app
The Beam pipeline is executed on a Flink session cluster, which is deployed by the Flink Kubernetes Operator. The application deployment mode where the Beam pipeline is deployed as a Flink job doesn’t seem to work (or I don’t understand how to do so yet) due to either a job submission timeout error or a failure to upload the job artifact. After the pipeline is deployed, we check the output of the application by sending text messages to the input Kafka topic.
Deploy the Flink Kubernetes Operator
First, to make it possible to add the webhook component, install the certificate manager on the minikube cluster. Then, use a Helm chart to install the operator. Version 1.8.0 is installed in the post.
kubectl create -f https://github.com/jetstack/cert-manager/releases/download/v1.8.2/cert-manager.yaml
helm repo add flink-operator-repo https://downloads.apache.org/flink/flink-kubernetes-operator-1.8.0/
helm install flink-kubernetes-operator flink-operator-repo/flink-kubernetes-operator
# NAME: flink-kubernetes-operator
# LAST DEPLOYED: Mon Jun 03 21:37:45 2024
# NAMESPACE: default
# STATUS: deployed
# REVISION: 1
# TEST SUITE: None
helm list
# NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
# flink-kubernetes-operator default 1 2024-06-03 21:37:45.579302452 +1000 AEST deployed flink-kubernetes-operator-1.8.0 1.8.0Deploy the Beam pipeline
First, create a Flink session cluster. In the manifest file, configure common properties, such as the Docker image, Flink version, cluster configuration, and pod template. These properties are applied to the Flink job manager and task manager. In addition, specify the replica and resource. We add a sidecar container to the task manager, and this SDK harness container is configured to execute Python user code - see the following job configuration.
# beam/word_len_cluster.yml
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: word-len-cluster
spec:
image: beam-python-example:1.16
imagePullPolicy: Never
flinkVersion: v1_16
flinkConfiguration:
taskmanager.numberOfTaskSlots: "10"
serviceAccount: flink
podTemplate:
spec:
containers:
- name: flink-main-container
volumeMounts:
- mountPath: /opt/flink/log
name: flink-logs
volumes:
- name: flink-logs
emptyDir: {}
jobManager:
resource:
memory: "2048Mi"
cpu: 2
taskManager:
replicas: 1
resource:
memory: "2048Mi"
cpu: 2
podTemplate:
spec:
containers:
- name: python-harness
image: beam-python-harness:2.56.0
args: ["-worker_pool"]
ports:
- containerPort: 50000
name: harness-port
The pipeline is deployed using a Kubernetes job, and the custom SDK harness image is used to execute the pipeline as a module. The first two arguments are application-specific. The rest of the arguments are for pipeline options. For more information about the pipeline arguments, see the pipeline options source and Flink Runner document. To execute Python user code in the sidecar container, we set the environment type to EXTERNAL and the environment config to localhost:50000.
# beam/word_len_job.yml
apiVersion: batch/v1
kind: Job
metadata:
name: word-len-job
spec:
template:
metadata:
labels:
app: word-len-job
spec:
containers:
- name: beam-word-len-job
image: beam-python-harness:2.56.0
command: ["python"]
args:
- "-m"
- "word_len.run"
- "--deploy"
- "--bootstrap_servers=demo-cluster-kafka-bootstrap:9092"
- "--runner=FlinkRunner"
- "--flink_master=word-len-cluster-rest:8081"
- "--job_name=beam-word-len"
- "--streaming"
- "--parallelism=3"
- "--flink_submit_uber_jar"
- "--environment_type=EXTERNAL"
- "--environment_config=localhost:50000"
- "--checkpointing_interval=10000"
restartPolicy: Never
Deploy the session cluster and job using the kubectl create command. The session cluster is created by the FlinkDeployment custom resource, and it manages the job manager deployment, task manager pod, and associated services. When we check the log of the job’s pod, we see that it does the following tasks:
- starts the Job Service after downloading the Jar file
- uploads the pipeline artifact
- submits the pipeline as a Flink job
- continuously monitors the job status
kubectl create -f beam/word_len_cluster.yml
# flinkdeployment.flink.apache.org/word-len-cluster created
kubectl create -f beam/word_len_job.yml
# job.batch/word-len-job created
kubectl logs word-len-job-p5rph -f
# WARNING:apache_beam.options.pipeline_options:Unknown pipeline options received: --checkpointing_interval=10000. Ignore if flags are used for internal purposes.
# WARNING:apache_beam.options.pipeline_options:Unknown pipeline options received: --checkpointing_interval=10000. Ignore if flags are used for internal purposes.
# INFO:root:Building pipeline ...
# INFO:apache_beam.runners.portability.flink_runner:Adding HTTP protocol scheme to flink_master parameter: http://word-len-cluster-rest:8081
# WARNING:apache_beam.options.pipeline_options:Unknown pipeline options received: --checkpointing_interval=10000. Ignore if flags are used for internal purposes.
# DEBUG:apache_beam.runners.portability.abstract_job_service:Got Prepare request.
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/config HTTP/1.1" 200 240
# INFO:apache_beam.utils.subprocess_server:Downloading job server jar from https://repo.maven.apache.org/maven2/org/apache/beam/beam-runners-flink-1.16-job-server/2.56.0/beam-runners-flink-1.16-job-server-2.56.0.jar
# INFO:apache_beam.runners.portability.abstract_job_service:Artifact server started on port 43287
# DEBUG:apache_beam.runners.portability.abstract_job_service:Prepared job 'job' as 'job-edc1c2f1-80ef-48b7-af14-7e6fc86f338a'
# INFO:apache_beam.runners.portability.abstract_job_service:Running job 'job-edc1c2f1-80ef-48b7-af14-7e6fc86f338a'
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "POST /v1/jars/upload HTTP/1.1" 200 148
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "POST /v1/jars/e1984c45-d8bc-4aa1-9b66-369a23826921_beam.jar/run HTTP/1.1" 200 44
# INFO:apache_beam.runners.portability.flink_uber_jar_job_server:Started Flink job as a403cb2f92fecee65b8fd7cc8ac6e68a
# INFO:apache_beam.runners.portability.portable_runner:Job state changed to STOPPED
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/jobs/a403cb2f92fecee65b8fd7cc8ac6e68a/execution-result HTTP/1.1" 200 31
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/jobs/a403cb2f92fecee65b8fd7cc8ac6e68a/execution-result HTTP/1.1" 200 31
# INFO:apache_beam.runners.portability.portable_runner:Job state changed to RUNNING
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/jobs/a403cb2f92fecee65b8fd7cc8ac6e68a/execution-result HTTP/1.1" 200 31
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/jobs/a403cb2f92fecee65b8fd7cc8ac6e68a/execution-result HTTP/1.1" 200 31
# ...After the deployment completes, we can see the following Flink session cluster and job related resources.
kubectl get all -l app=word-len-cluster
# NAME READY STATUS RESTARTS AGE
# pod/word-len-cluster-7c98f6f868-d4hbx 1/1 Running 0 5m32s
# pod/word-len-cluster-taskmanager-1-1 2/2 Running 0 4m3s
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# service/word-len-cluster ClusterIP None <none> 6123/TCP,6124/TCP 5m32s
# service/word-len-cluster-rest ClusterIP 10.104.23.28 <none> 8081/TCP 5m32s
# NAME READY UP-TO-DATE AVAILABLE AGE
# deployment.apps/word-len-cluster 1/1 1 1 5m32s
# NAME DESIRED CURRENT READY AGE
# replicaset.apps/word-len-cluster-7c98f6f868 1 1 1 5m32s
kubectl get all -l app=word-len-job
# NAME READY STATUS RESTARTS AGE
# pod/word-len-job-24r6q 1/1 Running 0 5m24s
# NAME COMPLETIONS DURATION AGE
# job.batch/word-len-job 0/1 5m24s 5m24sYou can access the Flink web UI using the kubectl port-forward command on port 8081. The job graph shows two tasks. The first task adds word elements into a fixed time window. The second task sends the average word length records to the output topic.
kubectl port-forward svc/flink-word-len-rest 8081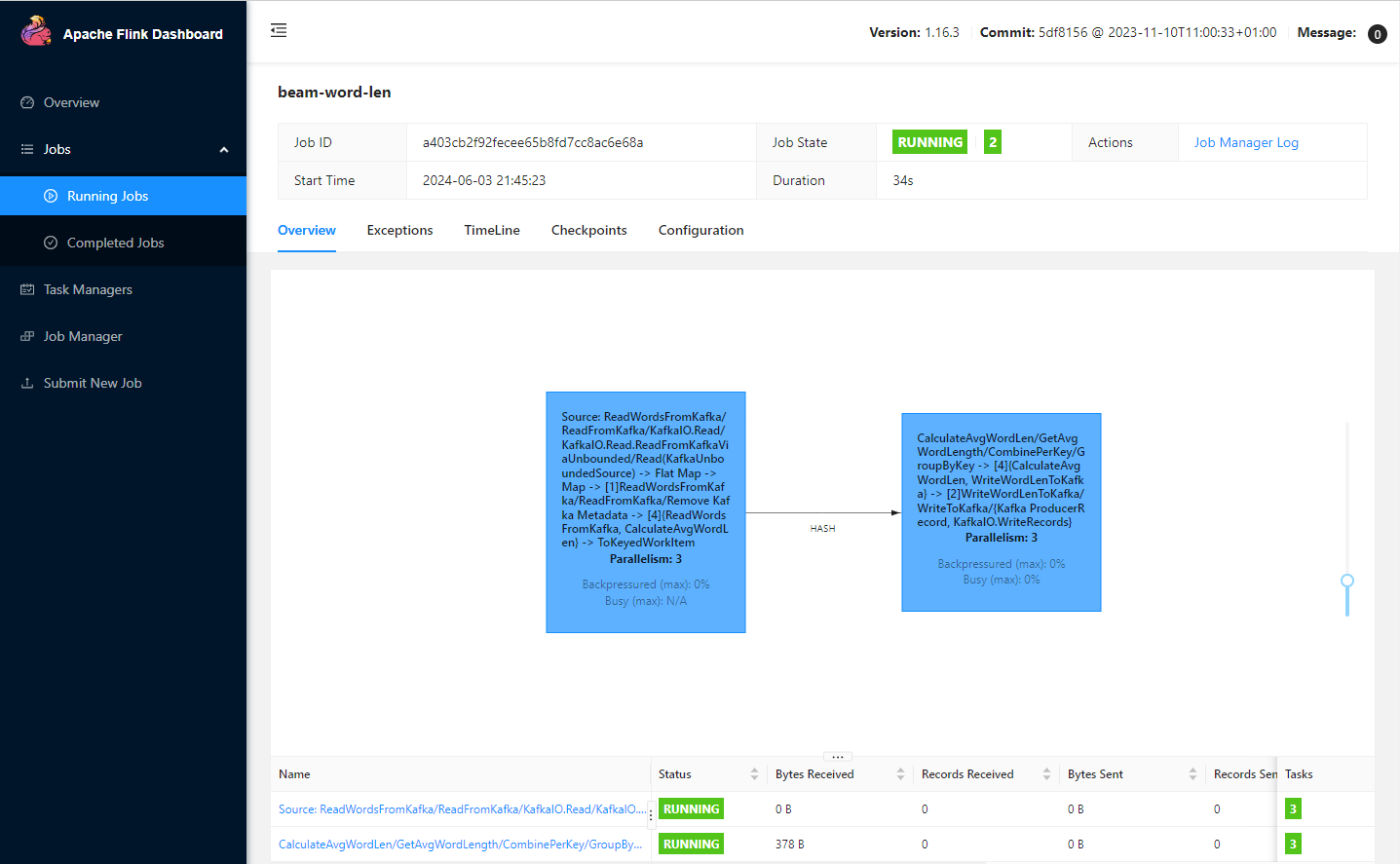
The Kafka I/O automatically creates a topic if it doesn’t exist, and we can see the input topic is created on kafka-ui.
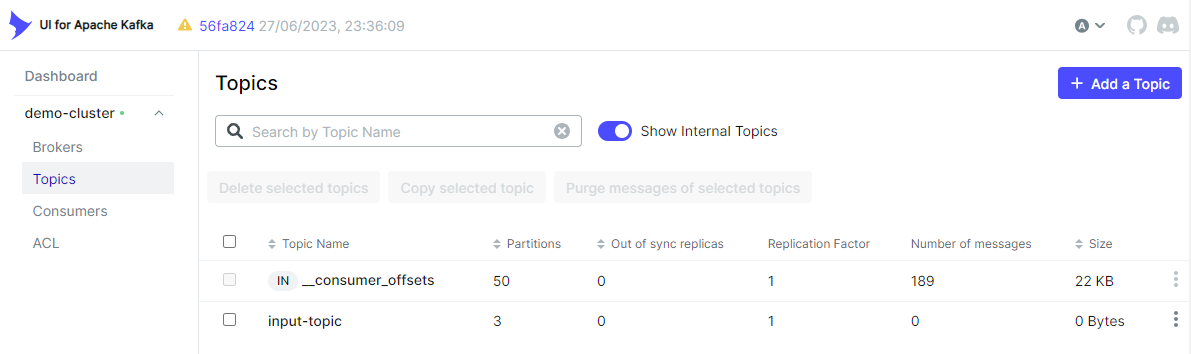
Kafka producer
A simple Python Kafka producer is created to check the output of the application. By default, the producer app sends random text from the Faker package to the input Kafka topic every one second.
# kafka/client/producer.py
import os
import time
from faker import Faker
from kafka import KafkaProducer
class TextProducer:
def __init__(self, bootstrap_servers: list, topic_name: str) -> None:
self.bootstrap_servers = bootstrap_servers
self.topic_name = topic_name
self.kafka_producer = self.create_producer()
def create_producer(self):
"""
Returns a KafkaProducer instance
"""
return KafkaProducer(
bootstrap_servers=self.bootstrap_servers,
value_serializer=lambda v: v.encode("utf-8"),
)
def send_to_kafka(self, text: str, timestamp_ms: int = None):
"""
Sends text to a Kafka topic.
"""
try:
args = {"topic": self.topic_name, "value": text}
if timestamp_ms is not None:
args = {**args, **{"timestamp_ms": timestamp_ms}}
self.kafka_producer.send(**args)
self.kafka_producer.flush()
except Exception as e:
raise RuntimeError("fails to send a message") from e
if __name__ == "__main__":
producer = TextProducer(
os.getenv("BOOTSTRAP_SERVERS", "localhost:29092"),
os.getenv("TOPIC_NAME", "input-topic"),
)
fake = Faker()
num_events = 0
while True:
num_events += 1
text = fake.text()
producer.send_to_kafka(text)
if num_events % 5 == 0:
print(f"<<<<<{num_events} text sent... current>>>>\n{text}")
time.sleep(int(os.getenv("DELAY_SECONDS", "1")))
Expose the Kafka bootstrap server on port 29092 using the kubectl port-forward command. Execute the Python script to start the producer app.
kubectl port-forward svc/demo-cluster-kafka-external-bootstrap 29092
python kafka/client/producer.pyWe can see the output topic (output-topic-beam) is created on kafka-ui.
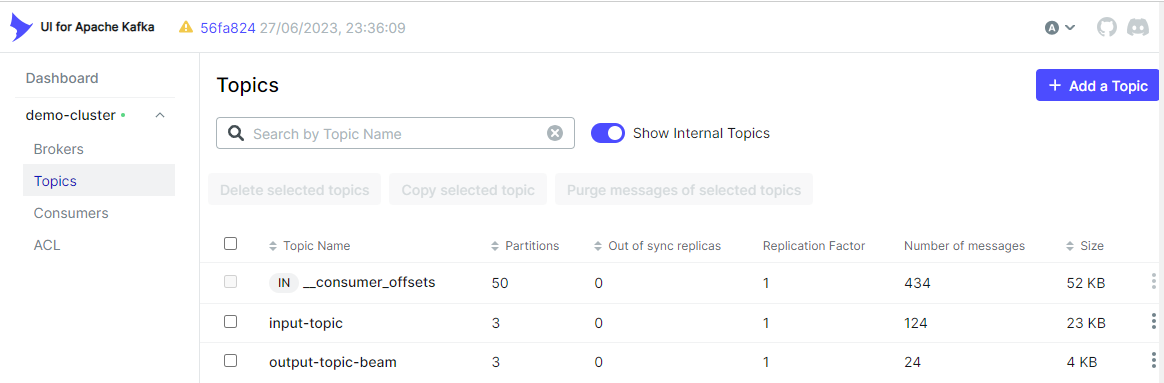
Also, we can check that the output messages are created as expected in the Topics tab.
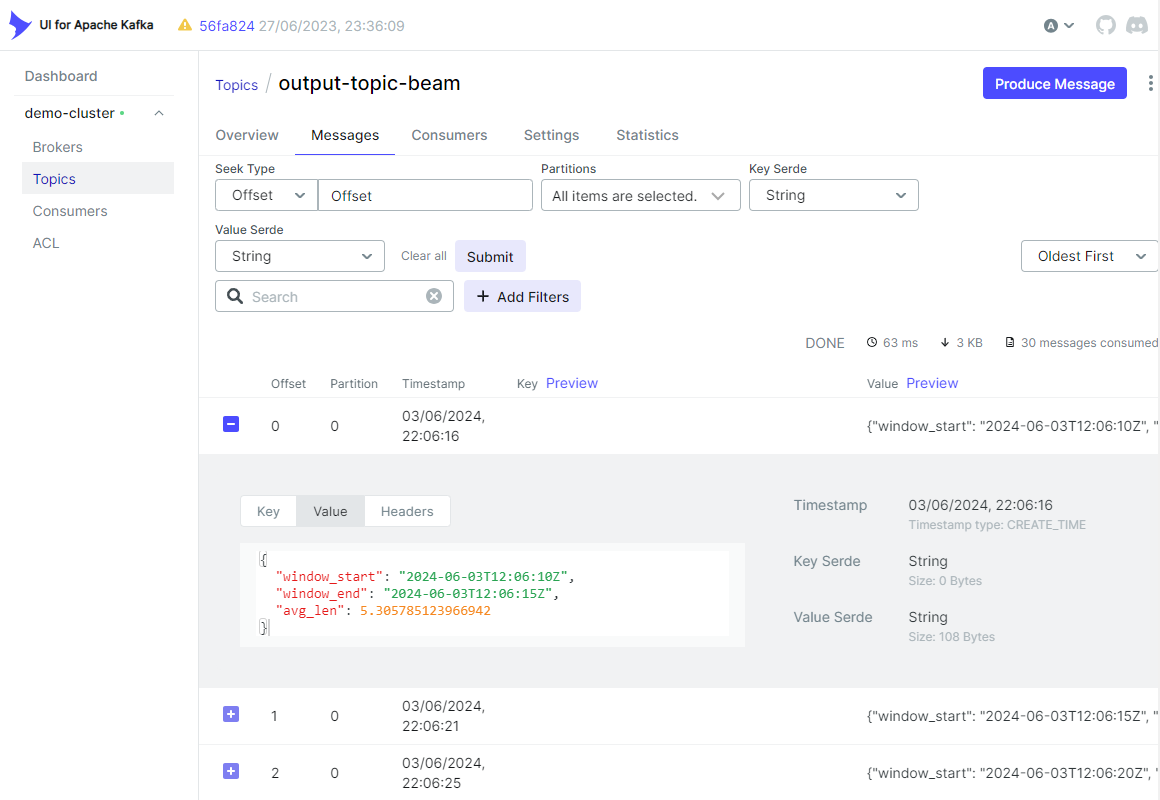
Delete resources
Delete the Kubernetes resources and the minikube cluster using the following steps.
## Delete the Flink Operator and related resources.
kubectl delete -f beam/word_len_cluster.yml
kubectl delete -f beam/word_len_job.yml
helm uninstall flink-kubernetes-operator
helm repo remove flink-operator-repo
kubectl delete -f https://github.com/jetstack/cert-manager/releases/download/v1.8.2/cert-manager.yaml
## Delete the Kafka cluster and related resources.
STRIMZI_VERSION="0.39.0"
kubectl delete -f kafka/manifests/kafka-cluster.yaml
kubectl delete -f kafka/manifests/kafka-ui.yaml
kubectl delete -f kafka/manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml
## Delete the minikube.
minikube delete