



blog
2016/05/27
Where's my PCollection.map()?Robert Bradshaw
Have you ever wondered why Beam has PTransforms for everything instead of having methods on PCollection? Take a look at the history that led to this (and other) design decisions.
Though Beam is relatively new, its design draws heavily on many years of experience with real-world pipelines. One of the primary inspirations is FlumeJava, which is Google’s internal successor to MapReduce first introduced in 2009.
The original FlumeJava API has methods like count and parallelDo on the PCollections. Though slightly more succinct, this approach has many disadvantages to extensibility. Every new user to FlumeJava wanted to add transforms, and adding them as methods to PCollection simply doesn’t scale well. In contrast, a PCollection in Beam has a single apply method which takes any PTransform as an argument.
| FlumeJava | Beam |
|---|---|
PCollection<T> input = …
PCollection<O> output = input.count()
.parallelDo(...);
|
PCollection<T> input = …
PCollection<O> output = input.apply(Count.perElement())
.apply(ParDo.of(...));
|
This is a more scalable approach for several reasons.
Where to draw the line?
Adding methods to PCollection forces a line to be drawn between operations that are “useful” enough to merit this special treatment and those that are not. It is easy to make the case for flat map, group by key, and combine per key. But what about filter? Count? Approximate count? Approximate quantiles? Most frequent? WriteToMyFavoriteSource? Going too far down this path leads to a single enormous class that contains nearly everything one could want to do. (FlumeJava’s PCollection class is over 5000 lines long with around 70 distinct operations, and it could have been much larger had we accepted every proposal.) Furthermore, since Java doesn’t allow adding methods to a class, there is a sharp syntactic divide between those operations that are added to PCollection and those that aren’t. A traditional way to share code is with a library of functions, but functions (in traditional languages like Java at least) are written prefix-style, which doesn’t mix well with the fluent builder style (e.g. input.operation1().operation2().operation3() vs. operation3(operation1(input).operation2())).
Instead in Beam we’ve chosen a style that places all transforms–whether they be primitive operations, composite operations bundled in the SDK, or part of an external library–on equal footing. This also facilitates alternative implementations (which may even take different options) that are easily interchangeable.
| FlumeJava | Beam |
|---|---|
PCollection<O> output =
ExternalLibrary.doStuff(
MyLibrary.transform(input, myArgs)
.parallelDo(...),
externalLibArgs);
|
PCollection<O> output = input
.apply(MyLibrary.transform(myArgs))
.apply(ParDo.of(...))
.apply(ExternalLibrary.doStuff(externalLibArgs));
|
Configurability
It makes for a fluent style to let values (PCollections) be the objects passed around and manipulated (i.e. the handles to the deferred execution graph), but it is the operations themselves that need to be composable, configurable, and extendable. Using PCollection methods for the operations doesn’t scale well here, especially in a language without default or keyword arguments. For example, a ParDo operation can have any number of side inputs and side outputs, or a write operation may have configurations dealing with encoding and compression. One option is to separate these out into multiple overloads or even methods, but that exacerbates the problems above. (FlumeJava evolved over a dozen overloads of the parallelDo method!) Another option is to pass each method a configuration object that can be built up using more fluent idioms like the builder pattern, but at that point one might as well make the configuration object the operation itself, which is what Beam does.
Type Safety
Many operations can only be applied to collections whose elements are of a specific type. For example, the GroupByKey operation should only be applied to PCollection<KV<K, V>>s. In Java at least, it’s not possible to restrict methods based on the element type parameter alone. In FlumeJava, this led us to add a PTable<K, V> subclassing PCollection<KV<K, V>> to contain all the operations specific to PCollections of key-value pairs. This leads to the same question of which element types are special enough to merit being captured by PCollection subclasses. It is not very extensible for third parties and often requires manual downcasts/conversions (which can’t be safely chained in Java) and special operations that produce these PCollection specializations.
This is particularly inconvenient for transforms that produce outputs whose element types are the same as (or related to) their input’s element types, requiring extra support to generate the right subclasses (e.g. a filter on a PTable should produce another PTable rather than just a raw PCollection of key-value pairs).
Using PTransforms allows us to sidestep this entire issue. We can place arbitrary constraints on the context in which a transform may be used based on the type of its inputs; for instance GroupByKey is statically typed to only apply to a PCollection<KV<K, V>>. The way this happens is generalizable to arbitrary shapes, without needing to introduce specialized types like PTable.
Reusability and Structure
Though PTransforms are generally constructed at the site at which they’re used, by pulling them out as separate objects one is able to store them and pass them around.
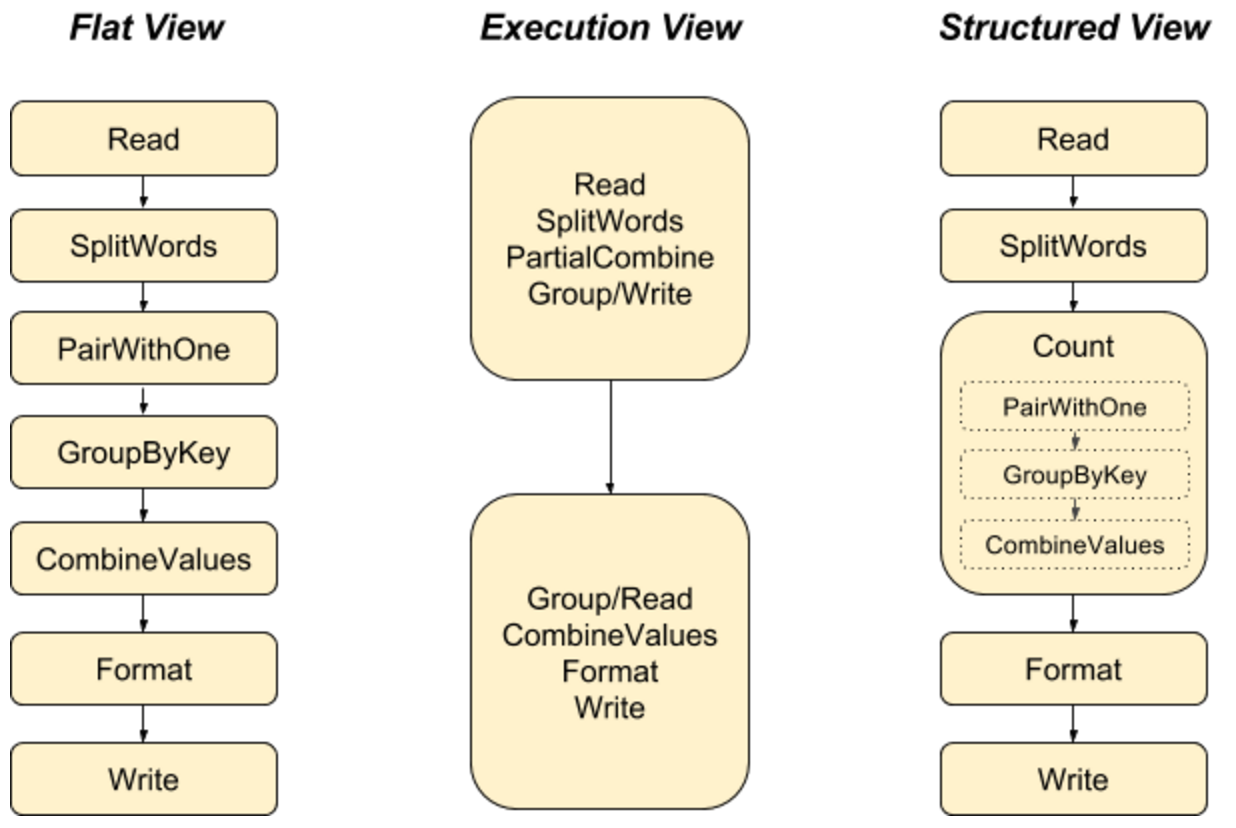
As pipelines grow and evolve, it is useful to structure your pipeline into modular, often reusable components, and PTransforms allow one to do this nicely in a data-processing pipeline. In addition, modular PTransforms also expose the logical structure of your code to the system (e.g. for monitoring). Of the three different representations of the WordCount pipeline below, only the structured view captures the high-level intent of the pipeline. Letting even the simple operations be PTransforms means there’s less of an abrupt edge to packaging things up into composite operations.
Summary
Although it’s tempting to add methods to PCollections, such an approach is not scalable, extensible, or sufficiently expressive. Putting a single apply method on PCollection and all the logic into the operation itself lets us have the best of both worlds, and avoids hard cliffs of complexity by having a single consistent style across simple and complex pipelines, and between predefined and user-defined operations.